MMFlood: A Multimodal Dataset for Flood Delineation from Satellite Imagery
- Citation Author(s):
-
Fabio Montello
 (LINKS Foundation)
Edoardo Arnaudo
(LINKS Foundation, PoliTo)
Claudio Rossi
(LINKS Foundation)
(LINKS Foundation)
Edoardo Arnaudo
(LINKS Foundation, PoliTo)
Claudio Rossi
(LINKS Foundation)
- Submitted by:
- Edoardo Arnaudo
- Last updated:
- DOI:
- 10.21227/bprf-jf62
- Data Format:
 3473 views
3473 views
- Categories:
- Keywords:
Abstract
Accurate flood delineation is crucial in many disaster management tasks, including, but not limited to: risk map production and update, impact estimation, claim verification, or planning of countermeasures for disaster risk reduction. Open remote sensing resources such as the data provided by the Copernicus ecosystem enable to carry out this activity, which benefits from frequent revisit times on a global scale. In the last decades, satellite imagery has been successfully applied to flood delineation problems, especially considering Synthetic Aperture Radar (SAR) signals. However, current remote mapping services rely on time-consuming manual or semi-automated approaches, requiring the intervention of domain experts. The implementation of accurate and scalable automated pipelines is hindered by the scarcity of large-scale annotated datasets. To address these issues, we propose MMFlood, a multimodal remote sensing dataset purposely designed for flood delineation. The dataset contains 1748 Sentinel-1 acquisitions, comprising 95 flood events distributed across 42 countries. Together with satellite imagery, the dataset includes the Digital Elevation Model (DEM), hydrography maps, and flood delineation maps provided by Copernicus EMS, which is considered as ground truth. We release MMFlood, comparing its relevance with similar earth observation datasets. Moreover, to set baseline performances, we conduct an extensive benchmark of the flood delineation task using state-of-art deep learning models, and we evaluate the performance gains of entropy-based sampling and multi-encoder architectures, which are respectively used to tackle two of the main challenges posed by MMFlood, namely the class unbalance and the multimodal setting.
Instructions:
Dataset Access and Specifications
You can download the MMFlood dataset from IEEE DataPort or alternatively Zenodo, at the following link: https://zenodo.org/record/6534637
Structure
The dataset is organized in directories, with a JSON file providing metadata and other information such as the split configuration we selected. Its internal structure is as follows:
activations/
├─ EMSR107-1/
├─ .../
├─ EMSR548-0/
│ ├─ DEM/
│ │ ├─ EMSR548-0-0.tif
│ │ ├─ EMSR548-0-1.tif
│ │ ├─ ...
│ ├─ hydro/
│ │ ├─ EMSR548-0-0.tif
│ │ ├─ EMSR548-0-1.tif
│ │ ├─ ...
│ ├─ mask/
│ │ ├─ EMSR548-0-0.tif
│ │ ├─ EMSR548-0-1.tif
│ │ ├─ ...
│ ├─ s1_raw/
│ │ ├─ EMSR548-0-0.tif
│ │ ├─ EMSR548-0-1.tif
│ │ ├─ ...
activations.json
- Each folder is named after the Copernicus EMS code it refers to. Since most of them actually contain more than one area, an incremental counter is added to the name, e.g.,
EMSR458-0,EMSR458-1and so on. - Inside each EMSR folder there are four subfolders containing every available modality and the ground truth, in GeoTIFF format:
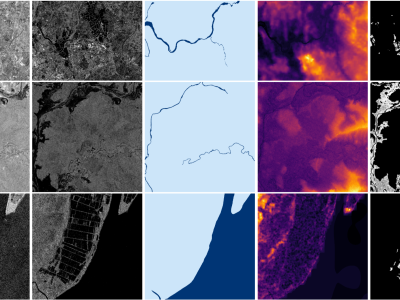
DEM: contains the Digital Elevation Modelhydro: contains the hydrography map for that region, if presents1_raw: contains the Sentinel-1 image in VV-VH formatmask: contains the flood map, rasterized from EMS polygons
- Every EMSR subregion contains a variable number of tiles. however, for the same area, each modality always contains the same amount of files with the same name. Names have the following format:
<emsr_code>-<emsr_region>_<tile_count>. For different reasons (retrieval, storage), areas larger than 2500x2500 pixels were divided in large tiles. - Note: Every modality is guaranteed to contain at least one image, except for the hydrography that may be missing.
Last, the activations.json contains informations about each EMS activation, as extracted from the Copernicus Rapid Mapping site, as such:
{
"EMSR107": {
...
},
"EMSR548": {
"title": "Flood in Eastern Sicily, Italy",
"type": "Flood",
"country": "Italy",
"start": "2021-10-27T11:31:00",
"end": "2021-10-28T12:35:19",
"lat": 37.435056244442684,
"lon": 14.954437192250033,
"subset": "test",
"delineations": [
"EMSR548_AOI01_DEL_PRODUCT_r1_VECTORS_v1_vector.zip"
]
},
}
Data specifications
| Image | Description | Format | Bands |
|---|---|---|---|
| S1 raw | Georeferenced Sentinel-1 imagery, IW GRD | GeoTIFF Float32 | 0: VV, 1: VH |
| DEM | MapZen Digital Elevation Model | GeoTIFF Float32 | 0: elevation |
| Hydrogr. | Binary map of permanent water basins, OSM | GeoTIFF Uint8 | 0: hydro |
| Mask | Manually validated ground truth label, Copernicus EMS | GeoTIFF Uint8 | 0: gt |
Image metadata
Every image also contains the following contextual information, as GDAL metadata tags:
<GDALMetadata>
<Item name="acquisition_date">2021-10-31T16:56:28</Item>
<Item name="code">EMSR548-0</Item>
<Item name="country">Italy</Item>
<Item name="event_date">2021-10-27T11:31:00</Item>
</GDALMetadata>
acquisition_daterefers to the acquisition timestamp of the Sentinel-1 imageevent_daterefers to official event start date reported by Copernicus EMS
Code and installation
To run this code, simply clone it into a directory of choice and create a python environment.
git clone git@github.com:edornd/mmflood.git && cd mmflood
python3 -m venv .venv
pip install -r requirements.txt
Everything goes through the run command. Run python run.py --help for more information about commands and their arguments.
Data preparation
To prepare the raw data by tiling and preprocessing, you can run: python run.py prepare --data-source [PATH_TO_ACTIVATIONS] --data-processed [DESTINATION]
Training
Training uses HuggingFace accelerate to provide single-gpu and multi-gpu support. To launch on a single GPU:
CUDA_VISIBLE_DEVICES=... python run.py train [ARGS]
You can find an example script with parameters in the scripts folder.
Testing
Testing is run on non-tiled images (the preprocessing will format them without tiling). You can run the test on a single GPU using the test command. At the very least, you need to point the script to the output directory. If no checkpoint is provided, the best one (according to the monitored metric) will be selected automatically. You can also avoid storing outputs with --no-store-predictions.
CUDA_VISIBLE_DEVICES=... python run.py test --data-root [PATH_TO_OUTPUT_DIR] [--checkpoint-path [PATH]]
Data Attribution and LicensesFor the realization of this project, the following data sources were used: