Artificial Intelligence

High quality perception is essential for autonomous driving (AD) systems. To reach the accuracy and robustness that are required by such systems, several types of sensors must be combined. Currently, mostly cameras and laser scanners (lidar) are deployed to build a representation of the world around the vehicle. While radar sensors have been used for a long time in the automotive industry, they are still under-used for AD despite their appealing characteristics (notably, their ability to measure the relative speed of obstacles and to operate even in adverse weather conditions).
- Categories:
 361 Views
361 Views
There are five types of data in the dataset, namely NORMAL, DoS, Probe, R2L and U2R. A total of 20,000 training samples were used during the experiment (5 classifications in total, 4000 samples for each classification). There are 4047 samples in the validation dataset, including 1000 samples each of NORMAL, DoS, and Probe types. 995 samples of R2L and 52 samples of U2R.
- Categories:
263 Views
This data is the embedding of abstracts of articles on echocardiography in Pubmed with the models of BERT, BioBERT, and SciBERT.
- Categories:
106 Views
This data is the embedding of abstracts of articles on artificial intelligence in Pubmed with the models of BERT, BioBERT, and SciBERT.
- Categories:
138 Views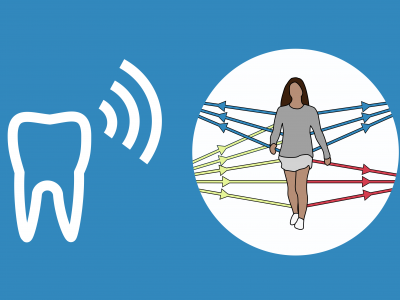
The human gait is unique and so is the impact of a walking human on the propagation of wireless signals within a wireless network. Using appropriate pattern recognition techniques, a person can thus be identified just from a time series of Received Signal Strength (RSS) measurements. This dataset holds bidirectional RSS measurements recorded within a mesh network of four Bluetooth sensor devices. During the measurements, a total of 14 subjects walked individually through the setup. A total of more than 10,000 recordings are provided.
- Categories:
640 Views
campus abnormal behavior recognition (CABR50) dataset, which contains 50 human abnormal action classes with an average of over 700 clips per class.
- Categories:
1031 Views
Synthetic Aperture Radar (SAR) satellite images are used increasingly more for Earth observation. While SAR images are useable in most conditions, they occasionally experience image degradation due to interfering signals from external radars, called Radio Frequency Interference (RFI). RFI affected images are often discarded in further analysis or pre-processed to remove the RFI.
- Categories:
330 Views
The data refer to times of payment from a hospital billing (HB) data set. The source data were collected from a hospital in the Netherlands over three years provided by Felix Mannhardt, Massimiliano de Leoni, Hajo A. Reijers and Wil M. P. van der Aalst in the paper with the title "Data-Driven Process Discovery - Revealing Conditional Infrequent Behavior from Event Logs". Based on the original data, duration data in four tasks are extracted for the analysis of patient patterns from a time perspective.
- Categories:
127 Views
Industrial cyber-physical systems (ICPS), which is the backbone of Industry 4.0, are the result of adapting emerging information communication technologies (ICT) to the industrial control systems (ICS). ICPS utilize autonomous robotic arms to accomplish manufacturing tasks. These arms follow a certain predetermined trajectory during the task.
In this dataset, we present four files generated from a setup that contains two Universal Robot UR3e collaborative robotic arms:
- Categories:
1111 Views
Database of energy consumption (Eihop) and Transmission Power P0, resulting from the manipulation of the variables: Nb (Number of bits per frame), i (Number of hops to the destination) and d (Distance between origin and destination) in Tmote Sky device Ultra-low power IEEE 802.15.4 (Moteiv). DataSet used in the learning process, via Machine Learning, of the transmission behavior of this device.
- Categories:
490 Views