Artificial Intelligence
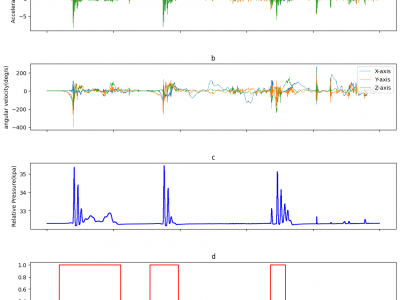
The data was collected by outfitting one of the players with the experimental balloon, which incorporated the embedded circuit and sensors. The sensors positioned at the top-right to the player within the bubble balloon, where a player stand inside. The sensors' data were collected at specific sampling frequencies (Accelerometer: 1000Hz, Gyroscope: 1000Hz, and Pressure: 40Hz). The experiment was conducted involving five different players. This approach allowed for the inclusion of diverse data samples, taking into account variations in player metrics, movements, and gameplay dynamics.
- Categories:
 218 Views
218 Views
Recently, contactless hand biometrics authentication has become increasingly popular among biometric researchers. These systems offer several advantages over traditional hand identification systems, including ease of capture and affordability, as they do not require the user’s hand to make direct contact with the sensor.
The Mobile Hand Biometrics (MHB) dataset includes images of fingerprint, palmprint, and hand geometry. These images are captured with a mobile camera without any physical contact, with no lighting conditions, and in free positions.
- Categories:
185 Views
Developing mind-controlled prosthetics that seamlessly integrate with the human nervous system is a significant challenge in the field of bioengineering. This project investigates the use of labelled brainwave patterns to control a bionic arm equipped with a sense of touch. The core objective is to establish a communication channel between the brain and the artificial limb, enabling intuitive and natural control while incorporating sensory feedback.
The project involves:
- Categories:
745 Views
Early detection of kidney illness can be achieved by training machine learning algorithms to discover patterns in patient data, such as imaging, test results, and medical history. This will enable rapid diagnosis and start of treatment regimens, which can improve patient outcomes. With 98.97% accuracy in CKD detection, the suggested TrioNet with KNN imputer and SMOTE fared better than other models. This comprehensive research highlights the model's potential as a useful tool in the diagnosis of chronic kidney disease (CKD) and highlights its capabilities.
- Categories:
1233 Views
One of the Dravidian language spoken majorly by 60 million people in and around Karnataka state of India is known as Kannada. It is one among 22 scheduled languages of India. Kannada langauge is written in Kannada scriptwhich has its traces back from kadamba script (325-550 AD). There are many languages which were used centuries back and aren’t being used currently whereas Kannada is one such language which is used even today for writing official documents and are being taught at schools which means it is going to be for many years.
- Categories:
287 Views
This dataset is the result on Voicebank+Demand testset by our proposed model in paper "MDCTCRN: A Lightweight CRN For Monaural Speech Enhancement with Modified DCT" The overall averge PESQ on Voicebank + Demand is 3.14.
- Categories:
50 Views
One of the key problems in 3D object detection is to reduce the accuracy gap between methods based on LiDAR sensors and those based on monocular cameras. A recently proposed framework for monocular 3D detection based on Pseudo-Stereo has received considerable attention in the community. However, three problems have been discovered in existing practices: (1) relying on a high-performance monocular depth estimator, (2) the generated image suffering from visual holes, deformations, and artifacts, and (3) being difficult to be compatible with geometry-based stereo detectors.
- Categories:
35 Views
This study presents a comprehensive dataset to analyze risk factors associated with cardiovascular disease. The dataset comprises various patient attributes, including gender, age, total cholesterol, HDL (high-density lipoprotein), triglycerides, non-HDL (non-high-density lipoprotein), NIH-Equ-2, and direct LDL (low-density lipoprotein). These attributes comprise 25,991 patient data, robustly representing a large population sample.
- Categories:
602 Views
The BirDrone dataset is compiled by aggregating images of small drones and birds sourced from various online datasets. It comprises 2970 high-resolution images (640x640 pixels), each featuring unique backdrops and lighting conditions. This dataset is designed to enhance machine learning models by simulating real-world scenarios.
Dataset Specifications:
- Categories:
1493 Views
The dataset presents user evaluations for itinerary recommendations generated with three algorithms, PP, PP+TS and PP+TP.
Users evaluated recommendations according to five properties:
- Categories:
153 Views