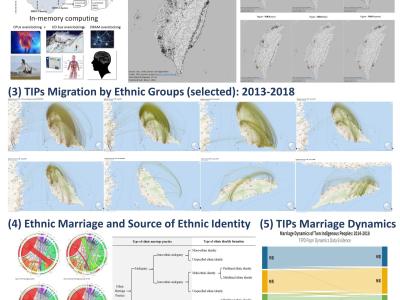
English (for details, see https://osf.io/e4rvz/)
Why the Research and Importance: Taiwan Indigenous Peoples (TIPs) are a branch of Polynesian-Malaysian (or Austronesian) ethnic groups in genetic and linguistic context. Since early 17th Century, TIPs had been playing a crucial role during the Great Marine Times of East Asia trades. There was a rich body of ethnographic, official and academic records on TIPs before 1940.
- Categories:






