Artificial Intelligence

Acoustic non-line-of-sight vehicle detection dataset. Complete multi-channel audio of vehicles passing through the intersection was captured at multiple intersections. It can be used for acoustic non-line-of-sight vehicle detection. The direction in which the vehicle entered the intersection, and the moments when the vehicle entered and left the line of sight were recorded in the file names, and the audio categories can be classified based on that moment. All audio files were stored in five folders to facilitate five-fold cross-validation.
- Categories:
 63 Views
63 Views
Acoustic non-line-of-sight vehicle detection dataset. Complete multi-channel audio of vehicles passing through the intersection was captured at multiple intersections. It can be used for acoustic non-line-of-sight vehicle detection. The direction in which the vehicle entered the intersection, and the moments when the vehicle entered and left the line of sight were recorded in the file names, and the audio categories can be classified based on that moment. All audio files were stored in five folders to facilitate five-fold cross-validation.
- Categories:
28 Views
The data comes from V2X-Sim full dataset. We keep vehicle onboard camera data, LiDAR data and infrastructure data in V2X-Sim. It encompasses a comprehensive and well-
synchronized collection of both infrastructure and vehicle sensor data. It also contains well-annotated ground truth data,which can support multiple perception tasks such as
detection, segmentation, and tracking. It includes six views of vehicle-side images and four views of infrastructure-side images. It collects 100 scenes in total, and every
scene includes 100 records.
- Categories:
40 Views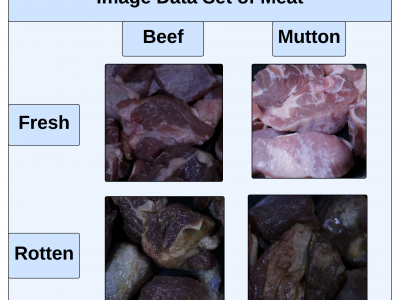
This paper presents an innovative Internet of Things (IoT) system that integrates gas sensors and a custom Convolutional Neural Network (CNN) to classify the freshness and species of beef and mutton in real time. The CNN, trained on 9,928 images, achieved 99% accuracy, outperforming models like ResNet-50, SVM, and KNN. The system uses three gas sensors (MQ135, MQ4, MQ136) to detect gases such as ammonia, methane, and hydrogen sulfide, which indicate meat spoilage.
- Categories:
660 Views
To provide a standardized approach for testing and benchmarking secure evaluation of transformer-based models, we developed the iDASH24 Homomorphic Encryption track dataset. This dataset is centered on protein sequence classification as the benchmark task. It includes a neural network model with a transformer architecture and a sample dataset, both used to build and evaluate secure evaluation strategies.
- Categories:
194 Views
The quality and safety of tea food production is of paramount importance. In traditional processing techniques, there is a risk of small foreign objects being mixed into Pu-erh sun-dried green tea, which directly affects the quality and safety of the food. To rapidly detect and accurately identify these small foreign objects in Pu-erh sun-dried green tea, this study proposes an improved YOLOv8 network model for foreign object detection. The method employs an MPDIoU optimized loss function to enhance target detection performance, thereby increasing the model's precision in targeting.
- Categories:
116 Views
The datasets are sourced from the Caltrans Performance Measurement System (PeMS) in California, which monitors and collects real-time traffic data from over 39,000 sensors deployed on major highways throughout the state. The PeMS system collects data every 30 seconds and aggregates it into 5-minute interval, with each sensor generating data for 288 time steps daily. Additionally, road network structure data is derived from the connectivity status and actual distances between sensors.
- Categories:
709 Views
The TiHAN-V2X Dataset was collected in Hyderabad, India, across various Vehicle-to-Everything (V2X) communication types, including Vehicle-to-Vehicle (V2V), Vehicle-to-Infrastructure (V2I), Infrastructure-to-Vehicle (I2V), and Vehicle-to-Cloud (V2C). The dataset offers comprehensive data for evaluating communication performance under different environmental and road conditions, including urban, rural, and highway scenarios.
- Categories:
1261 Views
Abstract—Most reinforcement learning algorithms for robotic arm control in sparse reward environments are primarily optimized for end-effector displacement control mode.
- Categories:
35 Views
This dataset includes two 2D medical image segmentation benchmark.
1. OD/OC Segmentation in Fundus Image
This dataset conprises five sub-datasets: Drishti-GS, RIM-ONE-r3, ORIGA, REFUGE, and the validation set of REFUGE2. Each image is cropped around the optic disc area. The size of all images is 512×512. The manual pixel-wise annotation is stored as a PNG image with the same size as the corresponding fundus image with the following labels:
128: Optic Disc (Grey color)
0: Optic Cup (Black color)
255: Background (White color)
- Categories:
166 Views