Artificial Intelligence

Any work using this dataset should cite the following paper:
- Categories:
 1887 Views
1887 Views
The video data set was obtained from the Mental Health Center of Renmin Hospital of Wuhan University, it includes 128 children and the video records the behavior of each subject (mainly upper body movements) during clinical intelligence evaluation. The ratio of training set, validation set and test set is 7:1:2.
- Categories:
232 Views
The video data set was obtained from the Mental Health Center of Renmin Hospital of Wuhan University, it includes 128 children and the video records the behavior of each subject (mainly upper body movements) during clinical intelligence evaluation. The ratio of training set, validation set and test set is 7:1:2.
- Categories:
112 Views
This dataset contains measurements of TPC-C benchmark executions in MySQL server deployed in Google Cloud Platform.
- Categories:
344 Views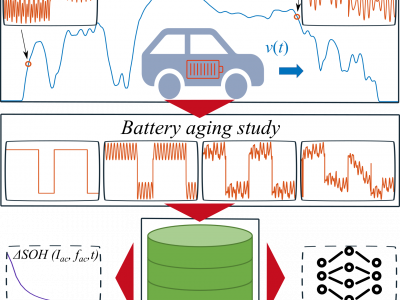
The SiCWell Dataset contains data of battery electric vehicle lithium-ion batteries for modeling and diagnosis purposes. In this experiment, automotive-grade lithium-ion pouch bag cells are cycled with current profiles plausible for electric vehicles.
The analysis of current ripples in electric vehicles and the corresponding aging experiments of the battery cells result in a dataset, which is composed of the following parts:
- Categories:
6476 Views
This dataset contains world news related to politics and also with the news article's available metadata.
- Categories:
1168 Views
This dataset contains world news related to Science and technology and also with the news article's available metadata.
- Categories:
793 Views
This dataset contains world news and also the news article's available metadata.
- Categories:
313 Views
This dataset contains world news related to Covid-19 and vaccine and also with the news article's available metadata.
- Categories:
716 Views
Data augmentation is commonly used to increase the size and diversity of the datasets in machine learning. It is of particular importance to evaluate the robustness of the existing machine learning methods. With progress in geometrical and 3D machine learning, many methods exist to augment a 3D object, from the generation of random orientations to exploring different perspectives of an object. In high-precision applications, the machine learning model must be robust with respect to the small perturbations of the input object.
- Categories:
248 Views