Artificial Intelligence

we construct the fine-grained landmark dataset for real urban street scenes. and utilize this dataset for fine-tuning. Specifically, based on the GSV dataset\cite{Ali_bey_2022} from Google Street View, we obtain image data with landmark bounding boxes by having annotators outline common landmarks in the urban street view images, while also recording the types of landmarks.
- Categories:
 5 Views
5 Views
One of the leading causes of early health detriment is the increasing levels of air pollution in major cities and eventually in indoor spaces. Monitoring the air quality effectively in closed spaces like educational institutes and hospitals can improve both the health and the life quality of the occupants. In this paper, we propose an efficient Indoor Air Quality (IAQ) monitoring and management system, which uses a combination of cutting-edge technologies to monitor and predict major air pollutants like CO2, PM2.5, TVOCs, and other factors like temperature and humidity.
- Categories:
66 Views
This upload contains code related to the article and is intended to help IEEE DataPort users understand how to use and reproduce our research methods. The code implements Remote Sensing image change Detection Network (CGLCS-Net) based on deep learning, including global-local context-aware selector (GLCAS) and subspace Self-Attention Fusion module (SSAF).
- Categories:
48 Views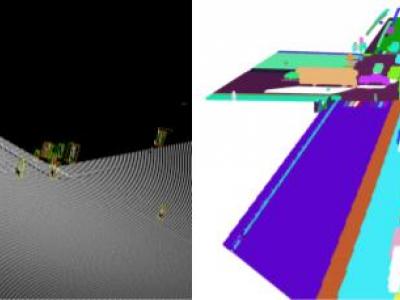
This paper is released with our paper titled “Annotated 3D Point Cloud Dataset for Traffic Management in Simulated Urban Intersections”. This paper proposed a 3D simulation based approach for generating an elevated LiDAR based 3D point cloud dataset simulating traffic in road intersections using Blender. We generated randomized and controlled traffic scenarios of vehicles and pedestrians movement around and within the intersection area, representing various scenarios. The dataset has been annotated to support 3D object detection and instance segmentation tasks.
- Categories:
64 Views
In this work, we study urban dynamics at the census tract level.
Information on census tracts and their corresponding geographic boundaries is available through the US Census Bureau survey. Each predetermined census tract is treated as a region. We use the GPS coordinates to compute the distance between two region nodes.
- Categories:
16 Views
Dataset for PerfCam: Digital Twinning for Production Lines Using 3D Gaussian Splatting and Vision Models
KTH Royal Institute of Technology, SCI; AstraZeneca, Sweden Operations
- Categories:
171 Views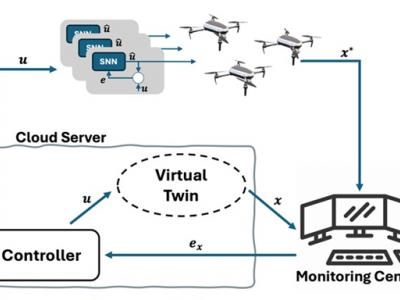
Presented study introduces a novel distributed cloud-edge framework for autonomous multi-UAV systems that combines the computational efficiency of neuromorphic computing with nature-inspired control strategies. The proposed architecture equips each UAV with an individual Spiking Neural Network (SNN) that learns to reproduce optimal control signals generated by a cloud-based controller, enabling robust operation even during communication interruptions.
- Categories:
157 Views
A new small aerial flame dataset, called the Aerial Fire and Smoke Essential (AFSE) dataset, is created which is comprised of screenshots from different YouTube wildfire videos as well as images from FLAME2. Two object categories are included in this dataset: smoke and fire. The collection of images is made to mostly contain pictures utilizing aerial viewpoints. It contains a total of 282 images with no augmentations and has a combination of images with only smoke, fire and smoke, and no fire nor smoke.
- Categories:
373 Views
The Explainable Sentiment Analysis Dataset provides annotated sentiment classification data for Amazon Reviews and IMDB Movie Reviews, facilitating the evaluation of sentiment analysis models with a focus on explainability. It includes ground-truth sentiment labels, model-generated predictions, and fine-grained classification results obtained from various large language models (LLMs), including both proprietary (GPT-4o/GPT-4o-mini) and open-source models (DeepSeek-R1 full and distilled models).
- Categories:
73 Views
Meituan Bench (MTB) is an enterprise-level benchmarking tool designed for time-series forecasting in real-world business scenarios. Built upon an open-source dataset derived from 10,000 real-world services across various business units, MTB provides a standardized evaluation framework for time-series prediction models. The dataset includes 200 representative services, capturing diverse traffic patterns essential for assessing forecasting performance.
- Categories:
36 Views