Machine Learning

This data set contains the JSON report zip files for the Ransomware execution in the sandbox. Also, it contains the CSV file for the count of API calls at the time of ransomware execution.
- Categories:
 442 Views
442 Views
This dataset was prepared to aid in the creation of a machine learning algorithm that would classify the white blood cells in thin blood smears of juvenile Visayan warty pigs. The creation of this dataset was deemed imperative because of the limited availability of blood smear images collected from the critically endangered species on the internet. The dataset contains 3,457 images of various types of white blood cells (JPEG) with accompanying cell type labels (XLSX).
- Categories:
3262 Views
The data are made of nine sets of measurements of four chipless RFID tags. The first two are made of 2600 measurements made at 160 centimeters (distance between the tag and the antenna) without (first) and with (second) initial background subtraction. The third set is made of 5600 measurements made in the range of 50 – 140 centimeters. The next six sets are measurements made to test models trained with the third set. All the measurements are made in the monostatic configuration.
- Categories:
316 Views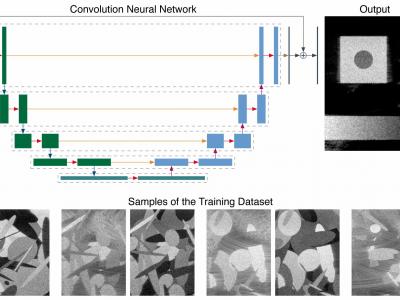
This repository contains the data related to the paper “CNN-Based Image Reconstruction Method for Ultrafast Ultrasound Imaging” (10.1109/TUFFC.2021.3131383). It contains multiple datasets used for training and testing, as well as the trained models and results (predictions and metrics). In particular, it contains a large-scale simulated training dataset composed of 31000 images for the three different imaging configuration considered (i.e., low quality, high quality, and ultrahigh quality).
- Categories:
3124 Views
EEG consists of collecting information from brain activity in the form of electrical voltage. Epileptic Seizure prediction and detection is a major sought after research nowadays. This dataset contains data from 11 patients of whom seizures are observed in EEG for 2 patients.
The total duration of seizures is 170 seconds. The number of channels is 16 and data is collected at 256Hz sampling rate.
The final dataset files in .csv format contain 87040 rows x 17 columns,
- Categories:
3186 Views
A Dynamic Multi-Objective Evolutionary Algorithm
- Categories:
287 Views
This dataset is related to dog activity and is sensor data.
- Categories:
691 Views
- Categories:
243 Views
With the rapid deployment of indoor Wi-Fi networks, Channel State Information (CSI) has been used for device-free occupant activity recognition. However, various environmental factors interfere with the stable propagation of Wi-Fi signals indoors, which causes temporal variation of CSI data. In this study, we investigated temporal CSI variation in a real-world housing environment and its impact on learning-based occupant activity recognition.
- Categories:
408 Views
Two dataset collected by USkin tactile sensors for detecting grasping stability and slip detection during lifting objects.
- Categories:
545 Views