Dataset for Towards Liveness Detection in Keystroke Dynamics: Revealing Synthetic Forgeries
- Citation Author(s):
-
Nahuel González
 (Laboratorio de Sistemas de Información Avanzados)
(Laboratorio de Sistemas de Información Avanzados)
- Submitted by:
- Nahuel Gonzalez
- Last updated:
- DOI:
- 10.21227/1ka3-er49
- Data Format:
- Links:
 532 views
532 views
- Categories:
- Keywords:
Abstract
Dataset used in the article "The Reverse Problem of Keystroke Dynamics: Guessing Typed Text with Keystroke Timings". CSV files with dataset results summaries, the evaluated sentences, detailed results, and scores. Results data contains training and evaluation ARFF files for each user, containing features of synthetic and legitimate samples as described in the article. The source data comes from three free text keystroke dynamics datasets used in previous studies, by the authors (LSIA) and two other unrelated groups (KM, and PROSODY, subdivided in GAY, GUN, and REVIEW). Two different languages are represented, Spanish in LSIA and English in KM and PROSODY.
The original dataset KM was used to compare anomaly-detection algorithms for keystroke dynamics in the article "Comparing anomaly-detection algorithms forkeystroke dynamic" by Killourhy, K.S. and Maxion, R.A. The original dataset PROSODY was used to find cues of deceptive intent by analyzing variations in typing patterns in the article "Keystroke patterns as prosody in digital writings: A case study with deceptive reviews and essay" by Banerjee, R., Feng, S., Kang, J.S., and Choi, Y.
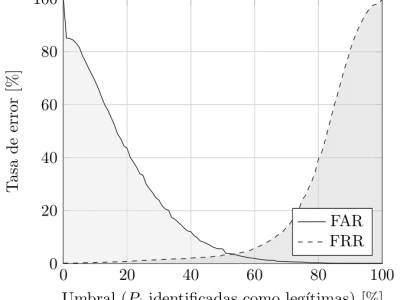
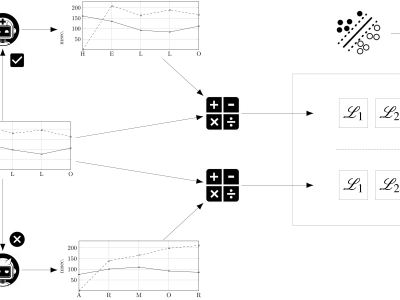
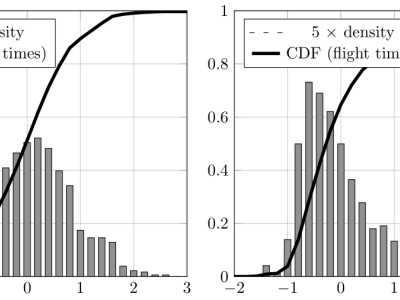
We introduce two strategies using higher order contexts and empirical distributions to generate artificial samples of keystroke timings, together with a liveness detection system for keystroke dynamics that leverages them as adversaries. To aid with this objective, a new derived feature based on the inverse function of the smoothed empirical cumulative distributions is presented. One of the proposed strategies outperforms other methods previously evaluated in the literature by a large margin, doubling and sometimes tripling their false acceptance rates, to around 15%, when data of the targeted user is available. If only general population data is available to an attacker, the liveness detection system achieves false acceptance and false rejection rates between 1% and 2%, consistently, over three datasets.
Instructions:
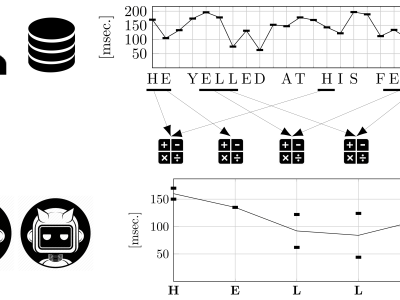
Each source dataset (LSIA, KM, and PROSODY) contains several typing sessions for each user, consisting of a sequence of keystrokes where its hold times (down-up) and flight times (down-down) were recorded alongside other relevant information. All of the latter was ignored. Each user session was split in sentences for the purpose of training and evaluation.
The source data and detailed results and scores for two experiments are included, named within-user and between-user. The first evaluates the proposed detector against synthetic forgeries where user-specific data from the targeted user was available, while the second uses general population data. Files named XXX.csv, where XXX is the name of the dataset, provide a summary of results, including false acceptance and false rejection rates, for each combination of training and evaluation strategy and every user. Files named XXX-ResultsBySentence.csv detail each synthetic forgery text and timing values. ARFF files provide the complete training and evaluation rows of derived features for each user and method.
The file CFS.zip corresponds to the correlation-based feature selection experiment to determine whether the proposed derived feature helps the classifier discriminate synthetic forgeries from the legitimate user samples. It contains files named CFS-XXX, where XXX is the name of the dataset, which list for each user the subset of features selected using correlation-based feature selection. The additional files provide average numeric values for correlation, gain ratio, info gain, and OneR evaluations.