Machine Learning

In order to train the joint contrastive representation learning module, we constructe a large Text Annotated Distortion, Appearance and Content (TADAC) image database.
- Categories:
 372 Views
372 Views
The LuFI-RiverSnap dataset includes close-range river scene images obtained from various devices, such as UAVs, surveillance cameras, smartphones, and handheld cameras, with sizes up to 4624 × 3468 pixels. Several social media images, which are typically volunteered geographic information (VGI), have also been incorporated into the dataset to create more diverse river landscapes from various locations and sources.
Please see the following links:
- Categories:
599 Views
This dataset comprises comprehensive information on chemical compounds sourced from the PubChem database, including detailed descriptions for each compound. Each entry in the dataset includes unique PubChem Compound Identifiers (CIDs), molecular structures, physicochemical properties, biological activities, and associated descriptive metadata. The dataset is designed to support research in drug discovery, chemical informatics, and other fields requiring extensive chemical compound information.
- Categories:
34 Views
Due to the difficulty in obtaining real samples and ground truth, the generalization performance and the fine-tuned performance are critical for the feasibility of stereo matching methods in real-world applications. However, the diverse datasets exhibit substantial discrepancies in disparity distribution and density, thus presenting a formidable challenge to the generalization and fine-tuning of the model.
- Categories:
22 Views
The data generated during this research includes several distinct components aimed at enhancing the understanding and application of call graph visualization and design pattern detection. This data is housed in a publicly accessible repository and comprises the following elements:
- Categories:
78 Views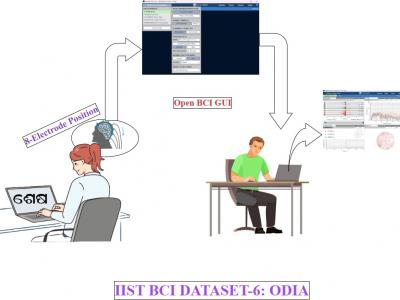
Brain-Computer Interface (BCI) is a technology that enables direct communication between the brain and external devices, typically by interpreting neural signals. BCI-based solutions for neurodegenerative disorders need datasets with patients’ native languages. However, research in BCI lacks insufficient language-specific datasets, as seen in Odia, spoken by 35-40 million individuals in India. To address this gap, we developed an Electroencephalograph (EEG) based BCI dataset featuring EEG signal samples of commonly spoken Odia words.
- Categories:
302 Views
This dataset contains simulation values from thermo-mechanical finite element analysis simulations using ABAQUS. Each simulation is one of 192 unique process parameter settings which includes varying laser power, scan speed, layer height and cooling assumptions. The geometry for each simulation is a hollow rectangluar box with rounded corners such that they form semi-circles. The wall thickness of each simulation is exactly the width of the focused laser.
- Categories:
122 Views
The dataset consists of around 335K real images equally distributed among 7 classes. The classes represent different levels of rain intensity, namely "Clear", "Slanting Heavy Rain", "Vertical Heavy Rain", "Slanting Medium Rain", "Vertical Medium Rain", "Slanting Low Rain", and "Vertical Low Rain". The dataset has been acquired during laboratory experiments and simulates a low-altitude flight. The system consists of a visual odometry system comprising a processing unit and a depth camera, namely an Intel Real Sense D435i.
- Categories:
200 Views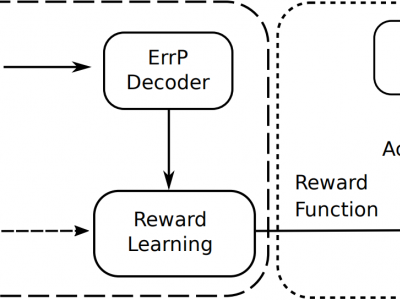
This dataset contains EEG error-related potential signals elicited by humans while observing an AI agent play an atari-based maze game.
- Categories:
125 Views
Study on Sleep Positions using a Wearable Device
This device constantly collects data about acceleration in three directions (tri-axial) 50 times a second (50 Hz). It has several components: a microcontroller for gathering and sending data (ESP8266), a battery (lithium-ion), a sensor for measuring acceleration (ADLX345 accelerometer), and a protective case made of plastic. The device can also store data temporarily on a microSD card in case the wireless connection is lost.
- Categories:
176 Views