Machine Learning
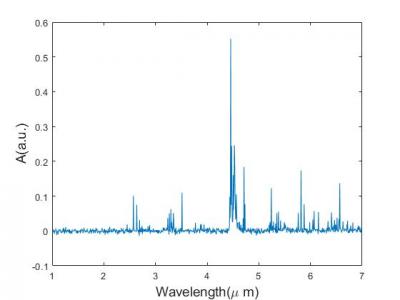
The dataset is the synthesized absorbance spectrum of a set of 9-gas mixtures following Beer-Lambert Law. We used the mid-infrared absorption cross-section spectra of C2H6, CH4, CO, H2O, HBr, HCl, HF, N2O, NO from the high-resolution transmission molecular absorption (HITRAN) database. Each sample contains 1,000 observations equally spaced between 1 µm and 7 µm wavelengths. The concentrations of the nine gases are mutually uncorrelated and follow uniform distribution between 0-10 µM.
- Categories:
 48 Views
48 Views
This is an accurately labeled dataset designed to support foreign bodies detection research in industrial production scenarios. In order to facilitate the reproduction of the results of the original paper, we provide this dataset for further research.
- Categories:
608 Views
The data set collected using a self-designed electronic nose (e-nose) involved eight Chinese liquor types, which are LanJinJiu with 38% alcohol concentration (LJJ38), LanJinJiu with 48% alcohol concentration (LJJ48), DaoHuaXiang with 42% alcohol concentration (DHX), LuZhouLaoJiao with 38% alcohol concentration (LZLJ), MianZhuDaQu with 38% alcohol concentration (MZDQ), QingJiu with 38% alcohol concentration (QJ), ShiLiXiang (SLX) with 40% alcohol concentration and BianFengHu with 40% alcohol concentration (BFH).
- Categories:
569 Views
We present below a sample dataset collected using our framework for synthetic data collection that is efficient in terms of time taken to collect and annotate data, and which makes use of free and open source software tools and 3D assets. Our approach provides a large number of systematic variations in synthetic image generation parameters. The approach is highly effective, resulting in a deep learning model with a top-1 accuracy of 72% on the ObjectNet data, which is a new state-of-the-art result.
- Categories:
641 Views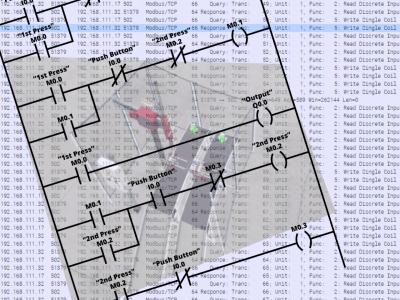
This dataset consisting of MODBUS/TCP communication was created using the Factory.IO simulator (trial version is available). The dataset contains different scenarios that control different industrial processes. For each scenario, files are provided to capture normal communication and communication with anomalies. The purpose of the dataset is to support research and evaluation of anomaly detection methods in the field of ICS.
- Categories:
2933 Views
The dataset originally was taken from DAIAD, which has the mechanism to monitor the water consumption in real time using a validated platform for different cities. These datasets had the record of different water consumption values taken from the smart water meters that indicates, total water consumption by different users in Litres with the time interval of one hour for a year.
- Categories:
5637 Views
The MPSC-rPPG dataset comprises photoplethysmograph (rPPG) data with the PPG ground truth, making it a perfect dataset to evaluate various algorithms for extracting PPG, measuring heart rate, heart rate variability from video. The dataset contains facial videos and Blood Volume Pulse (BVP) data captured concurrently.
- Categories:
4879 Views
COVID-19 tracing data are utilized to form two dataset networks, one is based on the virus transition between the world countries, as the dataset consists of 36 countries and 75 relationships between them. Whereas the other dataset is an attributed network based on the virus transition among the contact tracing in the Kingdom of Bahrain. This type of networks that is concerned in tracking a disease or virus was not formed based on COVID-19 virus transmission.
- Categories:
1311 Views
The Open Big Healthy Brains (OpenBHB) dataset is a large (N>5000) multi-site 3D brain MRI dataset gathering 10 public datasets (IXI, ABIDE 1, ABIDE 2, CoRR, GSP, Localizer, MPI-Leipzig, NAR, NPC, RBP) of T1 images acquired across 93 different centers, spread worldwide (North America, Europe and China). Only healthy controls have been included in OpenBHB with age ranging from 6 to 88 years old, balanced between males and females.
- Categories:
9968 Views
Distributed Denial of Service (DDoS) attacks first appeared in the mid-1990s, as attacks stopping legitimate users from accessing specific services available on the Internet. A DDoS attack attempts to exhaust the resources of the victim to crash or suspend its services. Time series modeling will help system administrators for better planning of resource allocation to defend against DDoS attacks. Different Time Series analysis techniques are applied to detect the DDoS attacks.
- Categories:
6637 Views