Machine Learning

Precise recognition of soybean pods is a crucial need for acquiring phenotypic characteristics, such as the number of productive pods and the quantity of seeds per plant. There exist several techniques for counting seeds, each with their own boundaries. An automated procedure, such as a machine learning algorithm, that takes a image as input and outputs the discrete count of a certain object of interest in the image, canbe used for this type of work.
- Categories:
 192 Views
192 Views
Current neural network solutions for channel estimation are frequently tested by training and testing on one example channel or similar channels. However, data-driven algorithms often degrade significantly on other channels which they are not trained on, because they cannot extrapolate their training knowledge. Online training can fine-tune the offline-trained neural networks to compensate for this degradation, but its feasibility is challenged by the tremendous computational resources required.
- Categories:
150 Views
Asthma is a common respiratory disease that affects people in many countries. It causes an attack that harms those patients and can cause death. This attack is related to many risk factors, including biosignals and environmental conditions. Here, we provide a dataset (584 entries) on the asthma biosignals and environmental conditions. This dataset was collected from 21 participants who have different levels of asthma disease. It was collected from the Makkah region in Saudi Arabia (Makkah and Jeddah cities) for three months, from 24-march – 30-June 2021.
- Categories:
259 Views
This dataset includes electronics repair guides from MyFixitDataset. From the MyFixit dataset, 50 repair manuals were randomly selected from each of the Mac, PC, Phone, and Electronics categories. These 200 repair manuals with 4754 distinct steps were to be selected and loaded into the Assembly Guidance Ontology. Each step was evaluated by the authors, and suitable parameters were assigned for the Digital Assembly Guidance System.
- Categories:
64 Views
- Categories:
115 Views
The JKU-ITS AVDM contains data from 17 participants performing different tasks with various levels of distraction.
The data collection was carried out in accordance with the relevant guidelines and regulations and informed consent was obtained from all participants.
The dataset was collected using the JKU-ITS research vehicle with automated capabilities under different illumination and weather conditions along a secure test route within the
- Categories:
728 Views
This is a compressed package containing nine multi-label text classification data sets, including AAPD, CitySearch, Heritage, Laptop, Ohsumed, RCV1, Restaurant, Reuters, and Sentihood.
- Categories:
29 Views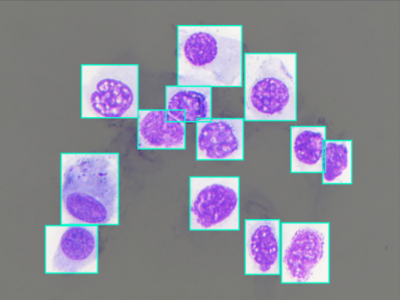
Nasal Cytology, or Rhinology, is the subfield of otolaryngology, focused on the microscope observation of samples of the nasal mucosa, aimed to recognize cells of different types, to spot and diagnose ongoing pathologies. Such methodology can claim good accuracy in diagnosing rhinitis and infections, being very cheap and accessible without any instrument more complex than a microscope, even optical ones.
- Categories:
638 Views
This database contains Synthetic High-Voltage Power Line Insulator Images.
There are two sets of images: one for image segmentation and another for image classification.
The first set contains images with different types of materials and landscapes, including the following landscape types: Mountains, Forest, Desert, City, Stream, Plantation. Each of the above-mentioned landscape types consists of 2,627 images per insulator type, which can be Ceramic, Polymeric or made of Glass, with a total of 47,286 distinct images.
- Categories:
488 Views
To address the challenges faced by patients with neurodegenerative disorders, Brain-Computer Interface (BCI) solutions are being developed. However, many current datasets lack inclusion of languages spoken by patients, such as Telugu, which is spoken by over 90 million people in India. To bridge this gap, we have created a dataset comprising Electroencephalograph (EEG) signal samples of commonly used Telugu words. Using the Open-BCI Cyton device, EEG samples were captured from volunteers as they pronounced these words.
- Categories:
410 Views