Image Processing

Experimental results.
- Categories:
 172 Views
172 Views
These three datasets cover Western, Chinese and Japanese food used for food instance counting and segmentation evaluation.
- Categories:
709 Views
Since there is no image-based personality dataset, we used the ChaLearn dataset for creating a new dataset that met the characteristics we required for this work, i.e., selfie images where only one person appears and his face is visible, labeled with the person's apparent personality in the photo.
- Categories:
3704 ViewsWe provide a dataset with synthetic white images for the Lytro Illum light field camera with precisely known microlens center coordinates.
The dataset consists of white images taken at different zoom settings as well as different microlens array offset and rotation.
The white images have been raytraced using a thin lens-based camera model. The synthesized white images incorporate natural as well as mechanical vignetting effects.
- Categories:
549 Views
n/a
- Categories:
102 Views
Calibration datasets used in the article Standard Plenoptic Cameras Mapping to Camera Arrays and Calibration based on DLT. These datasets were acquired with a Lytro Illum camera using two calibration grids with different sizes: 8 × 6 grid of 211 × 159 mm (Big Pattern) with approximately 26.5 mm cells, and 20×20 grid of 121.5 × 122 mm (Small Pattern) with approximately 6.1 mm cells. Each dataset acquired is composed of 66 fully observable poses of the calibration pattern.
- Categories:
848 Views
Research on damage detection of road surfaces has been an active area of research, but most studies have focused so far on the detection of the presence of damages. However, in real-world scenarios, road managers need to clearly understand the type of damage and its extent in order to take effective action in advance or to allocate the necessary resources. Moreover, currently there are few uniform and openly available road damage datasets, leading to a lack of a common benchmark for road damage detection.
- Categories:
4308 Views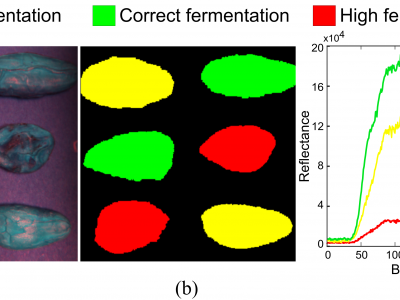
The target scene consists of a black card with six cocoa beans of three different fermentation levels (High, correct, and low fermentation), two beans for each class, whose false-color composite is shown in the provided Figure (a), ground-truth map is shown in Fig. (b), and Fig. (c) presents its representative spectral signatures. The spectral image was acquired by the AVT Stingray F-080B camera by acquiring one band each time from 350 - 950 nm. The acquired image has a spatial resolution of 1096x712 pixels and 300 spectral bands of 2 nm width.
- Categories:
827 Views
This data set is regarding the paper submitted to the IEEE Transactions on Molecular, Biological, and Multi-Scale Communications. The title of the paper is 'Molecular Signal Tracking and Detection Methods in Fluid Dynamic Channels' with the ID of TMBMC-TPS-19-0014.R2. The data are images taken from the particle image velocimetry (PIV) method and the Planar Laser-Induced fluorescence (PLIF) method. The images are being used to describe these two experimental methods for the molecular communication community.
- Categories:
201 Views
Dataset for Telugu Handwritten Gunintam
- Categories:
656 Views