cvs

This dataset, comprising 103,806 text entries, is a comprehensive resource for rumor detection on social media, constructed by merging benchmark collections including PHEME, LIAR Fake News, Twitter15, Twitter16, and ISOT Fake News. It features a binary classification schema (47% rumor, 53% non-rumor) and integrates original and adversarially augmented samples to enhance model robustness.
- Categories:
 23 Views
23 Views
This data collection focuses on capturing user-generated content from the popular social network Reddit during the year 2023. This dataset comprises 29 user-friendly CSV files collected from Reddit, containing textual data associated with various emotions and related concepts.
- Categories:
2167 Views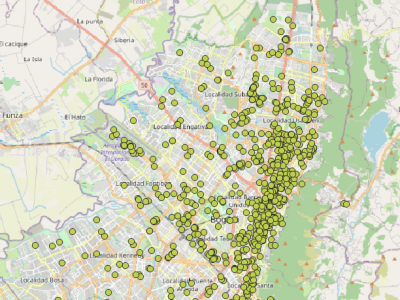
827 PoIs in Bogota D.C., Colombia, obtained from Foursquare. Format of the data is CSV with headers. The data include: id, geometry representation, name, category, latitude, longitude, and geohash.
- Categories:
194 Views
Intelligent Hybrid model to Enhance Time Series Models for Predicting Network Traffic, the proposed research has used the clustering approach to handle the ambiguity from the entire network data for enhancing the existing time series models.
- Categories:
2724 Views
Stable and efficient walking strategies for humanoid robots usually relies on assumptions regarding terrain characteristics. If the robot is able to classify the ground type at the footstep moment, it is possible to take preventive actions to avoid falls and to reduce energy consumption.
This dataset contains raw data from 10 inertial and torque sensors of a humanoid robot, sampled after the impact between foot and ground. There are two types of data: simulated using gazebo and data from a real robot.
- Categories:
585 Views