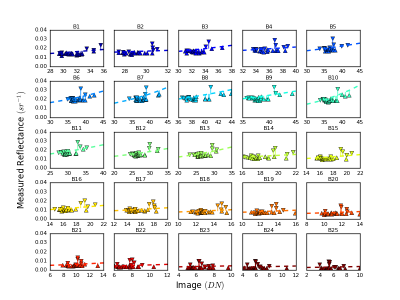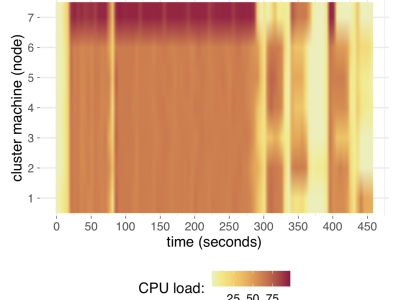
We introduce a benchmark of distributed algorithms execution over big data. The datasets are composed of metrics about the computational impact (resource usage) of eleven well-known machine learning techniques on a real computational cluster regarding system resource agnostic indicators: CPU consumption, memory usage, operating system processes load, net traffic, and I/O operations. The metrics were collected every five seconds for each algorithm on five different data volume scales, totaling 275 distinct datasets.
- Categories: