
Open dataset from Machine Learning Repository of Center for Machine Learning and Intelligent Systems at the University of California, Irvine.
- Categories:

Data set of 26/11 Mumbai attack is based on Mumbai Terrorist Attacks 2008 India Ministry of External Affairs Dossier and News reports.
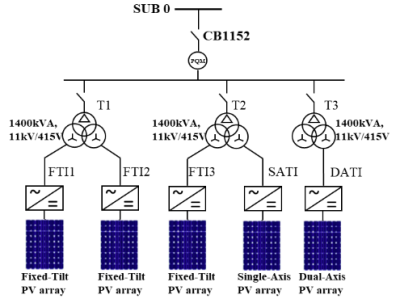
The datasets consist of operational data and detailed information of three inverter transformers in a 3.275 MW PV plant in the outskirt of Brisbane, Australia. The data includes load current, top-oil temperature, moisture in top oil, ambient temperature, solar irradiance and individual current harmonics (up to 31st order). The time interval of the data is either 1 minute or 3 seconds (dependent on the data type). The data can be used to study the ageing of inverter transformers in this PV plant.


This dataset is a set of eighteen directed networks that represents message exchanges among Twitter accounts during eighteen crisis events. The dataset comprises 645,339 anonymized unique user IDs and 1,396,709 edges that are labeled with respect to Plutchik's basic emotions (anger, fear, sadness, disgust, joy, trust, anticipation, and surprise) or "neutral" (if a tweet conveys no emotion).

This dataset contains requests execution times for comparison of direct requests and requests via API gateway to test API.

Background: Insomnia as one of the dominant diseases of traditional Chinese medicine (TCM) has been extensively studied in recent years. To explore the novel approaches of research on TCM diagnosis and treatment, this paper presents a strategy for the research of insomnia based on machine learning.
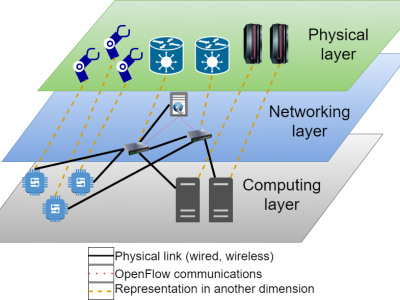
The rise of the Internet of Things (IoT) has opened new research lines that focus on applying IoT applications to domains further beyond basic user-grade applications, such as Industry or Healthcare. These domains demand a very high Quality of Service (QoS), mainly a very short response time. In order to meet these demands, some works are evaluating how to modularize and deploy IoT applications in different nodes of the infrastructure (edge, fog, cloud), as well as how to place the network controllers, since these decisions affect the response time of the application.

This dataset contains nearly 1 Million unique movie reviews from 1150 different IMDb movies spread across 17 IMDb genres - Action, Adventure, Animation, Biography, Comedy, Crime, Drama, Fantasy, History, Horror, Music, Mystery, Romance, Sci-Fi, Sport, Thriller and War. The dataset also contains movie metadata such as date of release of the movie, run length, IMDb rating, movie rating (PG-13, R, etc), number of IMDb raters, and number of reviews per movie.
Vehicular networks have various characteristics that can be helpful in their inter-relations identifications. Considering that two vehicles are moving at a certain speed and distance, it is important to know about their communication capability. The vehicles can communicate within their communication range. However, given previous data of a road segment, our dataset can identify the compatibility time between two selected vehicles. The compatibility time is defined as the time two vehicles will be within the communication range of each other.