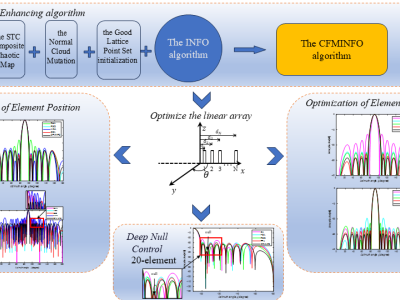
Abstract—This manuscript introduces the Chaos Fusion Mutation INFO algorithm (CFMINFO), which integrates multiple strategies and updates vector positions through three core processes. These processes incorporate Good Point Set initialization, Sine-Tent-Cosine (STC) chaotic parameterization, and Normal Cloud Mutation strategies. The algorithm is characterized by its simplicity, rapid convergence, and ability to avoid local optima. To validate its performance, CFMINFO is applied to the optimization of linear arrays.
- Categories: