SocialCD-3K
- Citation Author(s):
-
Guanghui Fu
- Submitted by:
- Hongzhi Qi
- Last updated:
- DOI:
- 10.21227/jb3w-j696
- Data Format:
 364 views
364 views
- Categories:
- Keywords:
Abstract
We sourced our data by crawling comments from the “Zoufan” blog within the Weibo social platform. Subsequently, a team of qualified psychologists were enlisted to annotate the data. In our study, strict data preprocessing measures were adopted to protect users’ privacy.
SocialCD-3K (Cognitive Distortion Classification)
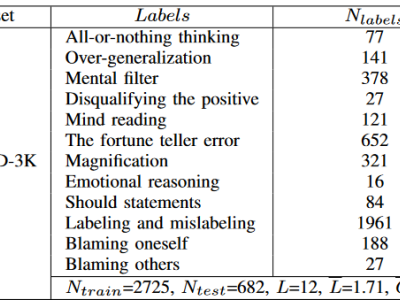
- Labels and Number of Samples:
- All-or-nothing thinking: 77
- Over-generalization: 141
- Mental filter: 378
- Disqualifying the positive: 27
- Mind reading: 121
- The fortune teller error: 652
- Magnification: 321
- Emotional reasoning: 16
- Should statements: 84
- Labeling and mislabeling: 1961
- Blaming oneself: 188
- Blaming others: 27
- Data Split:
- Training set: 2725 samples
- Test set: 682 samples
- Average Number of Labels per Sample: 1.71
- Average Number of Words per Post: 42.56
Instructions:
If you use this dataset in your research, please cite the following paper:
@misc{qi2023evaluating,
title={Evaluating the Efficacy of Supervised Learning vs Large Language Models for Identifying Cognitive Distortions and Suicidal Risks in Chinese Social Media},
author={Hongzhi Qi and Qing Zhao and Changwei Song and Wei Zhai and Dan Luo and Shuo Liu and Yi Jing Yu and Fan Wang and Huijing Zou and Bing Xiang Yang and Jianqiang Li and Guanghui Fu},
year={2023},
eprint={2309.03564},
archivePrefix={arXiv},
primaryClass={cs.CL}
}







Nice