Other
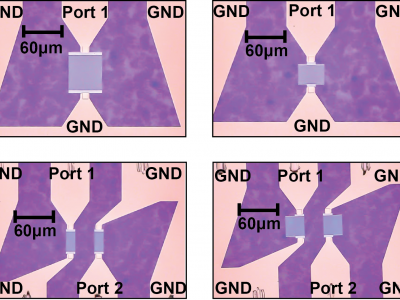
This work presents a comprehensive study of the performance of Sezawa surface acoustic wave (SAW) devices in SweGaN QuanFINE® ultrathin GaN/SiC platform, reaching frequencies above 14 GHz for the first time. Sezawa mode frequency scaling is achieved due to the elimination of the thick buffer layer typically present in epitaxial GaN technology. Finite element analysis (FEA) is first performed to find the range of frequencies over which the Sezawa mode is supported in the grown structure.
- Categories:
 136 Views
136 Views
This dataset is used to design patent and many machines can be designed using this dataset.
This is a very important dataset to do breakthrough. One of the secrets behind invention is revealed in these datasets.
Part of this design, with manually done tabulated calculations were submitted as the proposal design (for innovation challenge) proposed by the author, in the small concept paper to Ministry of Railways, Govt. of India in the year 2017.
As the Excel files(using LibreOffice) are given, so no paper is written is for it.
- Categories:
1919 Views
the data of Gaussian Process Regression Based Traffic Prediction and Rate Coordination for Service Chain Congestion Optimization
- Categories:
178 Views
Cycling data of shared bike users
- Categories:
32 Views
<p>cnki dataset</p>
- Categories:
128 Views
Data of the paper "Goal Orientation in Music Composition and Other Social Behaviors Leading to the Common Quantitative Law".
- Categories:
95 Views
Microrobot swarms have powerful functions and reconfigurable collective behaviors, which enable them as a possible way to completely solve the low execution efficiency and poor practicability of a single microrobot. However, some general deficiencies hinder the advancement of research in the application of microrobot swarms. For example, the limited number of individuals and the tiny spatial size make the current microrobot swarms too insignificant to meet practical needs. To
- Categories:
10 Views
Models of the electrical machines are used in the process of development control system and verification of them. Nowadays multiphase machines are attracting attention due to their reliability; however, standard MATLAB libraries are limited by 5-phase and 3-phase models. This paper considers a universal model of 3-, 5-, 6-, 7-, 9-phase permanent magnet synchronous motor. The model was developed using standard blocks of MATALB Simulink and can be used as a component of SimPowerSystem. Simulation results are provided as well as a link to the library for use free of charge.
- Categories:
435 Views