Other

This dataset is hosted on IEEE DataPort(TM), a data repository created by IEEE to facilitate research reproducibility. A Systematic Literature Review SLR is presented on information retrieval for IoT and WoT scenarios, containing the definition of the research questions and the selection strategy. We specify the inclusion and exclusion criteria in conjunction with the quality assurance criteria. The data extraction procedure is then outlined.
- Categories:
 233 Views
233 Views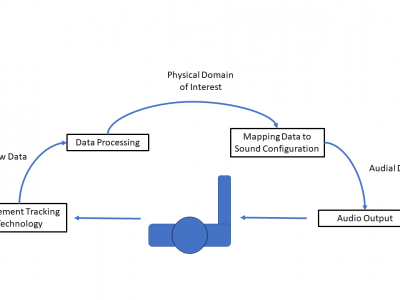
Movement sonification is emerging as a useful tool for rehabilitation, with increasing evidence in support of its use. To create such a system requires component considerations outside of typical sonification design choices, such as the dimension of movement to sonify, section of anatomy to track, and methodology of motion capture. This review takes this emerging and highly diverse area of literature and keyword-code existing real-time movement sonification systems, to analyze and highlight current trends in these design choices, as such providing an overview of existing systems.
- Categories:
14 Views
A hypothetical Landau potential is used to compute the qualitative trend of the dielectric response that evolves as 1/second_derivative of the landau Potential.
- Categories:
62 Views
We collect 22 large benchmark circuits from RevLib and 34 small circuits from IBM Qiskit Lib and those used by SABRE. We generate the scheduling sequences and physical circuits of the circuits by our Heuristic greedy algorithm and Monte Carlo tree search algorithm. The DataSet consists of the input and output. The formal consists of the 56 circuits and their initial mappings. The latter consists of the scheduling sequences and physical circuits generated by our two algorithms.
- Categories:
106 Views
Please cite the following paper when using this dataset:
N. Thakur, “MonkeyPox2022Tweets: A large-scale Twitter dataset on the 2022 Monkeypox outbreak, findings from analysis of Tweets, and open research questions,” Infect. Dis. Rep., vol. 14, no. 6, pp. 855–883, 2022, DOI: https://doi.org/10.3390/idr14060087.
Abstract
- Categories:
3552 Views
A folder that contains the Matlab code for the proposed design tool of the paper "Analysis and Preliminary Design of a Passive Upper Limb Exoskeleton" (authors: G. Vazzoler, P. Bilancia, G. Berselli, M. Fontana, A. Frisoli) can be freely downloaded.
- Categories:
167 Views
This dataset is for researching main content extraction from web pages as a archived mongoDB file and postgresql dump file.
This dataset has crawled MHTML files of web pages from nine languages (Korean, Japanese, Indonesian, French, Russian, Saudi Arabian (Arabic), and Chinese).
Releated Resources:
- Categories:
171 Views
Emulating a RT task and measuring the response latency of its thread by means of the high-resolution testing tool Cyclictest. The thread was clocked at 10ms, and a FIFO scheduling policy was used, with the thread being assigned the highest priority. Measurements were performed in distinct testing environments, some of which had best effort concurrent threads competing for the machine resources. For this purpose, the workload generator tool stress was used.
- Categories:
520 Views
Bitcoin (BTC), ether (ETH), gridcoin (GRC), curecoin (CURE), and foldingcoin (FLDC) market capitalizations in USD.
- Categories:
75 Views
A conventional virtual flight test generally refers to a 3-DOF dynamic flight test in a wind tunnel. In the wind tunnel test, the model aircraft is connected to the strut through a 3-DOF rotation mechanism and installed in the wind tunnel test section so that the model displacement is constrained but has 3 degrees of angular motion freedom. Open-loop and closed-loop control of the aircraft model is achieved by directly driving the rudder surface or by using commands from the flight control system.
- Categories:
234 Views