Machine Learning

This dataset offers both Channel State Information (CSI) and Beamforming Feedback Information (BFI) data for human activity classification, featuring 20 distinct activities performed by three subjects across three environments. Collected in both line-of-sight (LoS) and non-line-of-sight (NLoS) scenarios, this dataset enables researchers to explore the complementary roles of CSI and BFI in activity recognition and environmental characterization.
- Categories:
 318 Views
318 Views
This dataset enables advanced Wi-Fi sensing applications, including multi-subject monitoring for home surveillance, remote healthcare, and entertainment. It focuses on Beamforming Feedback Information (BFI) as a proxy for Channel State Information (CSI), eliminating the need for firmware modifications and enabling single-capture data collection across multiple channels between an access point (AP) and stations (STAs).
- Categories:
129 Views
As various modalities of genomic data are accumulating, methods to integrate across multi-omics datasets are becoming important. Error-correcting output codes (ECOC) is an ensemble learning strategy for solving a multiclass problem thru a decoding process that aggregates the predictions of multiple classifiers. Thus, it lends itself naturally to aggregating predictions across multiple views as well. We applied the ECOC to multi-view learning to see if this strategy can enhance classifier performance as compared to traditional techniques.
- Categories:
52 Views
Jamming devices pose a significant threat by disrupting signals from the global navigation satellite system (GNSS), compromising the robustness of accurate positioning. Detecting anomalies in frequency snapshots is crucial to counteract these interferences effectively. The ability to adapt to diverse, unseen interference characteristics is essential for ensuring the reliability of GNSS in real-world applications. We recorded a dataset with our own sensor station at a German highway with two interference classes and one non-interference class.
- Categories:
295 Views
Hyperthermia is a thermal treatment for cancer which kills cancer cells by applying heat. Among different heating approaches, magnetic hyperthermia uses heat generation of magnetic nanoparticles to achieve local treatment. Magnetic nanoparticles induce heat when stimulated by an alternating magnetic field, and the heating efficiency depends on multiple parameters including magnetic properties of magnetic nanoparticles and magnetic field used to stimulate the nanoparticles.
- Categories:
83 Views
This dataset contains original and augmented versions of the Korean Call Content Vishing (KorCCVi v2) dataset used in the study titled, "Enhancing Voice Phishing Detection Using Multilingual Back-Translation and SMOTE: An Empirical Study." The dataset addresses challenges of data imbalance and asymmetry in Korean voice phishing detection, leveraging data augmentation techniques such as multilingual back-translation (BT) with English, Chinese, and Japanese as intermediate languages, and Synthetic Minority Oversampling Technique (SMOTE).
- Categories:
580 Views
I met Yeshua Ben Joseph, Yahowah, the living Allaha in person in 2007, and this work, may it be entirely unto His grace.
The Cone of Perception 4th Edition Table of Contents
1. Introduction to the 4th Edition
2. The Meaning of Now
3. The Geometric Pattern of Perception Theorems
i. Math for Transforming a Circle into a Cone
a. Theorem 1 - Difference in the Circumferences of Two Circles
i. Lemma1 ii. Lemma 2 iii.Lemma 3 iv.Lemma 4 v. Lemma 5
b. Theorem 2 - Equilateral Triangle of Instantaneous Velocity = Average Velocity i. Lemma8
- Categories:
74 Views
Thanks be to Yeshua ben Joseph, Yahowah, the living One Allaha.
This work is a attempt to describe various braches of mathematics and the analogies betwee them. Namely:
1) Symbolic Analogic 2) Lateral Algebraic Expressions 3) Calculus of Infin- ity Tensors Energy Number Synthesis 4) Perturbations in Waves of Calculus Structures (Group Theory of Calculus) 5) Algorithmic Formation of Symbols (Encoding Algorithms)
- Categories:
74 Views
Description
- Categories:
70 Views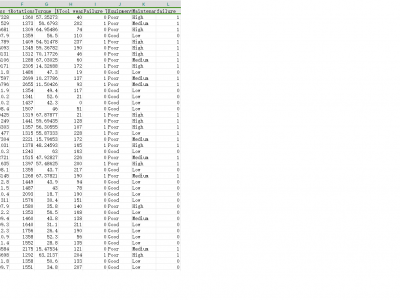
The Machine Failure Predictions Dataset (D_2) is a real-world dataset sourced from Kaggle, containing 10,000 records and 14 features pertinent to IIoT device performance and health status. The binary target feature, 'failure', indicates whether a device is functioning (0) or has failed (1). Predictor variables include telemetry readings and categorical features related to device operation and environment. Data preprocessing included aggregating features related to failure types and removing non-informative features such as Product ID.
- Categories:
340 Views