Machine Learning

EmoSurv is a dataset containing keystroke data along with emotion labels. Timing and frequency data is recorded while participants are typing free and fixed texts before and after being induced specific emotions. These emotions are: Anger, Happiness, Calmness, Sadness, and Neutral state.
First, data is collected while the participant is in a neutral state. Then, the participant watches an eliciting video. Once the emotion is induced in the participant, he types another fixed and free text.
- Categories:
 4094 Views
4094 Views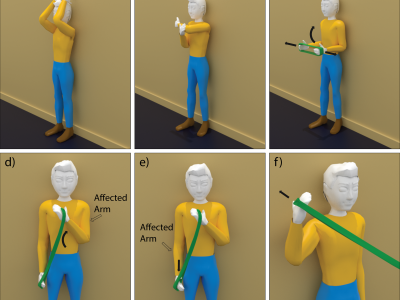
Shoulder Physiotherapy Activity Recognition 9-Axis Dataset (SPARS9x)
Suggested uses of this dataset include performing supervised classification analysis of physiotherapy exercises, or to perform out-of-distribution detection analysis with unlabeled activities of daily living data.
Description:
- Categories:
1931 Views
CMSO CFAR NN classifier
- Categories:
108 Views
The dataset provides Abilify Oral user reviews and ratings for drug’s satisfaction, effectiveness, and ease of use on different age groups.
- Categories:
300 Views
This India-specific COVID-19 tweets dataset has been curated using the large-scale Coronavirus (COVID-19) Tweets Dataset. This dataset contains tweets originating from India during the first week of each of the four phases of nationwide lockdowns initiated by the Government of India. For more information on filtering keywords, please visit the primary dataset page.
Announcements:
- Categories:
5129 Views
PT7 Web is an annotated Portuguese language Corpus built from samples collected from Sep 2018 to Mar 2020 from seven Portuguese-speaking countries: Angola, Brazil, Portugal, Cape Verde, Guinea-Bissau, Macao e Mozambique. The records were filtered from Common Crawl — a public domain petabyte-scale dataset of webpages in many languages, mixed together in temporal snapshots of the web, monthly available [1]. The Brazilian pages were labeled as the positive class and the others as the negative class (non-Brazillian Portuguese).
- Categories:
587 Views
Parallel sentences in English and French, with mathematical expressions tokenized. The French sentences were extracted from course notes on error-correcting codes authored by Dr. Monica Nevins, University of Ottawa.
- Categories:
142 Views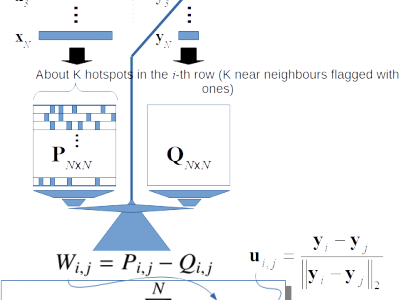
From state-of-the-art visualization algorithms, we distill six working principles which are, by hypothesis, sufficient to produce visual projections qualitatively similar to those obtained with these state-of-the-art algorithms. These working principles are presented through the geometrical reasoning of the classical Multidimensional Scaling algorithm, and their effectiveness is illustrated through a novel straightforward algorithm for image visualization.
- Categories:
124 Views
The dataset has Gaussian Blobs of varying samples, centers and features. The number of samples ranges from 500 to 50,000. Similarly, the number of centers varies from 2 to 100, while the number of features varies from 2 to 2048. These different sets of Gaussian blobs can be used for testing clustering algorithms for their scalability and effectiveness. There are two kinds of files inside the compressed sets. Files ending with "_X.csv" consist of datapoints, while the files ending with "_y.csv" represent respective class data.
- Categories:
2881 Views
The dataset is composed of digital signals obtained from a capacitive sensor electrodes that are immersed in water or in oil. Each signal, stored in one row, is composed of 10 consecutive intensity values and a label in the last column. The label is +1 for a water-immersed sensor electrode and -1 for an oil-immersed sensor electrode. This dataset should be used to train a classifier to infer the type of material in which an electrode is immersed in (water or oil), given a sample signal composed of 10 consecutive values.
- Categories:
2399 Views