Image Processing

Activated Sludge Phase-contrast Microscopic Image
- Categories:
 114 Views
114 Views
The anomaly detection in photovoltaic (PV) cell electroluminescence (EL) image is of great significance for the vision-based fault diagnosis. Many researchers are committed to solving this problem, but a large-scale open-world dataset is required to validate their novel ideas. We build a PV EL Anomaly Detection (PVEL-AD) dataset for polycrystalline solar cell, which contains 36,543 near-infrared images with various internal defects and heterogeneous background. This dataset contains anomaly-free images and anomalous images with 10 different categories.
- Categories:
6729 Views
Document layout analysis (DLA) plays an important role for identifying and classifying the different regions of digital documents in the context of Document Understanding tasks. In light of this, SciBank seeks to provide a considerable amount of data from text (abstract, text blocks, caption, keywords, reference, section, subsection, title), tables, figures and equations (isolated equations and inline equations) of 74435 scientific articles pages. Human curators validated that these 12 regions were properly labeled.
- Categories:
2150 Views
This CoFSM dataset contains the supplemental material of TIP3157450 (Multimodal remote sensing image datasets). The CoFSM dataset contains six types of modal images (multi temporal-optical, infrared-optical, depth-optical, map-optical, SAR-optical andnight-day). Each modal type includes 10 groups of images, and each set of images has corresponding ground truth points.
- Categories:
544 Views
This dataset consists of 1878 labeled images of flowers from blackberry trees from the specie Rubus L. subgenus Rubus Watson. These are white flowers with five petals that blossom in the spring through summer. The images were collected using an Intel RealSense D435i camera inside a greenhouse.
This images were inicially collected to support a robotic autonomous pollination project.
- Categories:
830 Views
The experiment is based on the open source RSRP data provided by Huawei Technologies Co., LTD. It measures RSRP of 415,244 signal receiving points in 180 dense urban communication cells.
- Categories:
1315 Views
We provided a new set of extreme low-light datasets of short exposure raw images in RGB format and long-exposure reference images of the same scenes.
- Categories:
171 Views
This is a collection of images.
- Categories:
135 Views
This dataset was prepared to aid in the creation of a machine learning algorithm that would classify the white blood cells in thin blood smears of juvenile Visayan warty pigs. The creation of this dataset was deemed imperative because of the limited availability of blood smear images collected from the critically endangered species on the internet. The dataset contains 3,457 images of various types of white blood cells (JPEG) with accompanying cell type labels (XLSX).
- Categories:
3536 Views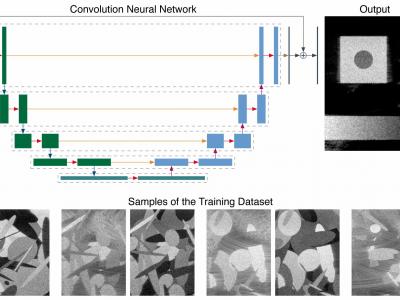
This repository contains the data related to the paper “CNN-Based Image Reconstruction Method for Ultrafast Ultrasound Imaging” (10.1109/TUFFC.2021.3131383). It contains multiple datasets used for training and testing, as well as the trained models and results (predictions and metrics). In particular, it contains a large-scale simulated training dataset composed of 31000 images for the three different imaging configuration considered (i.e., low quality, high quality, and ultrahigh quality).
- Categories:
3409 Views