Computational Intelligence

800x600
Normal
0
7.8 磅
0
2
false
false
false
EN-US
ZH-CN
X-NONE
MicrosoftInternetExplorer4
- Categories:
 156 Views
156 Views
D U C 2 0 0 2 dataset (https://www-nlpir.nist.gov/projects/duc/guidelines/2002.html) processed through doc2vec (https://github.com/jhlau/doc2vec)
This dataset includes the documents embeddings of the full DUC 2002 in the following configurations:
- Categories:
881 Views
Our dataset includes three parts: MNIST-rot, MNIST-scale, and MNIST-rand.
MNIST-rot is generated by randomly rotating
each sample in the MNIST testing dataset in $[0,2\pi]$.
We generated MNIST-scale by randomly scaling
the ratio of the area occupied by the symbol over that of the entire image by a factor
in $[0.5,1]$, and generated MNIST-rand by scaling and
rotating images in MNIST testing dataset simultaneously.
- Categories:
905 Views
Deep learning belongs to the scope of artificial intelligence, which has attracted researchers all over the world. The CNN is one the most popular techniques of deep learning. In this paper, the WLAN (wireless local area network) localization is given by SVD (singular value decomposition) noise-reduction and CNN (convolutional neural network).
- Categories:
412 Views
ARLab dataset with images used to train object grasping points. There are 4692 object images for training and testing.
- Categories:
121 Views
An effective use of electrochemical Energy Storage Systems (ESSs) is mandatory for improving the performances of next generation electric vehicles and hybrid electric vehicles, as well as of smart grid and microgrid systems.
- Categories:
20800 Views
The dataset contains the simulation results on two stochastic games -- box pushing and distributed sensor network (DSN). The setting of parameters is given in the manuscript named "A Gradient-Based Reinforcement Learning Algorithm for Multiple Cooperative Agents".
- Categories:
262 Views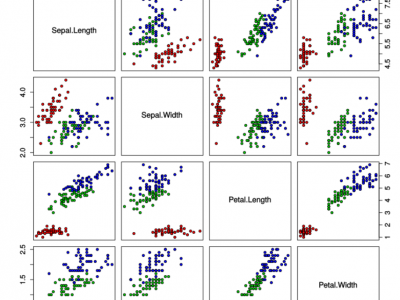
The Iris flower data set or Fisher's Iris data set is a multivariate data set .The data set consists of 50 samples from each of three species of Iris (Iris setosa, Iris virginica and Iris versicolor). Four features were measured from each sample: the length and the width of the sepals and petals, in centimeters. Based on the combination of these four features, Fisher developed a linear discriminant model to distinguish the species from each other.
- Categories:
446 Views
The data format is described as follows:
Event: {‘acc’: array([[x_axis], [y_axis], [z_axis], ‘gyr’,array([x_axis], [y_axis], [z_axis], ‘label’: No ]
No =1 means acceleration.
No =2 means normal driving.
No =3 means collision.
No =4 means left turn.
No =5 means right turn.
- Categories:
4860 Views
With the advent of huge data availability and cheap processing power to derive insights from data ,applications of Big Data and Machine Learning are gaining popularity in every industry. Now, Predicting about future is no more an alternate but a necessity to increase efficiency with accurate output. Forecasting for a shorter duration (Nowcasting) fits perfectly in this space to estimate the final production for better planning and control.
- Categories:
771 Views