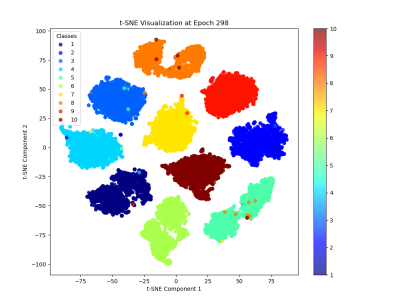
Meituan Bench (MTB) is an enterprise-level benchmarking tool designed for time-series forecasting in real-world business scenarios. Built upon an open-source dataset derived from 10,000 real-world services across various business units, MTB provides a standardized evaluation framework for time-series prediction models. The dataset includes 200 representative services, capturing diverse traffic patterns essential for assessing forecasting performance.
- Categories: