Artificial Intelligence

Opportunity++ is a precisely annotated dataset designed to support AI and machine learning research focused on the multimodal perception and learning of human activities (e.g. short actions, gestures, modes of locomotion, higher-level behavior).
- Categories:
 2109 Views
2109 Views
In this paper, we consider unmanned aerial vehicles (UAVs) equipped with a visible light communication (VLC) access point and coordinated multipoint (CoMP) capability that allows users to connect to more than one UAV. UAVs can move in 3-dimensional (3D) at a constant acceleration, where a central server is responsible for synchronization and cooperation among UAVs. The effect of accelerated motion in UAV is necessary to be considered. We define the data rate for each user type, CoMP, and non-CoMP.
- Categories:
731 Views
MNIST
- Categories:
167 Views
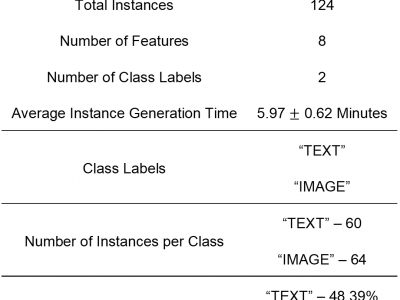
Human intention is an internal, mental characterization for acquiring desired information. From
interactive interfaces, containing either textual or graphical information, intention to perceive desired
information is subjective and strongly connected with eye gaze. In this work, we determine such intention by
analyzing real-time eye gaze data with a low-cost regular webcam. We extracted unique features (e.g.,
Fixation Count, Eye Movement Ratio) from the eye gaze data of 31 participants to generate the dataset
- Categories:
645 Views
This dataset is a Verilog-a implementation of a dynamic compact model of ferroelectric capacitance. It can be run with a SPICE-type circuit simulator.
Researchers using this dataset should cite it as follows: Ning Feng, Hao Li, Chang Su, Lining Zhang, Qianqian Huang,Runsheng Wang, and Ru Huang, A Dynamic Compact Model for Ferroelectric Capacitance, IEEE Electron Device Letters, DOI: 10.1109/LED.2022.3141413
- Categories:
286 ViewsThe data collection of the human subjects' brainwaves was performed using a specific experiment of showing a set of pictures that stimulate different emotions on the human subjects. In order to create this kind of experiment, a Java application is developed by us to simulate the visual experiment with the IAPS. It is a simple Java application developed in Eclipse IDE. The main purpose of the application is to collect subjects' credential information and show in sequence the selected set of images from IAPS.
- Categories:
359 Views
We have long known that the characterization of protein three-dimensional structure is key to obtaining a detailed understanding of protein function. Computational approaches to protein structure characterization have largely addressed a narrow formulation of the problem, where the goal is the determination of one structure, also known as the native structure, from a given protein amino-acid sequence. However, many researchers over the years have argued for broadening our view of proteins to account for the multiplicity of native structures.
- Categories:
208 Views
NLOS/LOS acoustic signal dataset, including 4 rooms, 12,800 data, labeled as NLOS and LOS.
- Categories:
195 Views
The dataset provides textures generated from elliptical cosine and sinc fractional Brownian field models.
- Categories:
102 Views