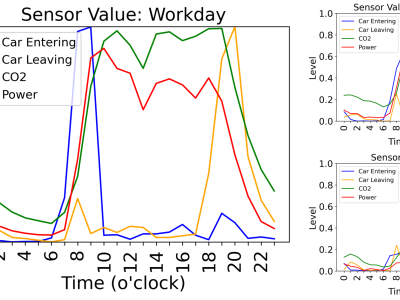
This is the market data of Bitcoin in terms of price and volume from August 2015 to August 2021. The time interval of sampling is selected as four-hour, that is to say, we choose every kind of price and volume every of four-hour as the original data. The original market data of Bitcoin are obtained from Poloniex, one of the most active crypto-asset exchanges.
Download link on XBlock: http://xblock.pro/#/dataset/5
- Categories: