Artificial Intelligence

This is the video dataset for SFDM paper. Only the first 30 seconds are to be used. The last 10 seconds are extended so that the trimming of the video does not make each clip end abruptly before 30 seconds.
File naming style: {case study number}{sequence}{clip number}{opt: falsely detected as other sequence}.webm
- Categories:
 130 Views
130 Views
In order to develop and analyse the performance of large-scale colored point cloud upsampling, we built a large-scale colored point cloud dataset for training and evaluating the upsampling network. This large-scale colored point cloud dataset consists of 121 original colored point clouds, 43 of which were scanned by us, while the other 78 were obtained from the SIAT-PCQD, Moving Picture Experts Group (MPEG) point cloud, and Greyc 3D colored mesh database. These point clouds cover six categories, including animals, plants, toys, sculptures, people and others.
- Categories:
220 Views
Brain-Computer Interface (BCI) technology facilitates a direct connection between the brain and external devices by interpreting neural signals. It is critical to have datasets that contain patient's native languages while developing BCI-based solutions for neurological disorders. However, present BCI research lacks appropriate language-specific datasets, particularly for languages such as Telugu, which is spoken by more than 90 million people in India.
- Categories:
332 Views
The dataset1 includes fake&real news propagation networks on Twitter built according to fact-check information and the news retweet graphs were originally extracted by [FakeNewsNet](https://github.com/KaiDMML/FakeNewsNet).The statistics of the dataset is shown below:| Data | #Graphs | #Total Nodes | #Total Edges | #Avg.
- Categories:
104 Views
Abstract
- Categories:
3150 Views
This study investigates the integration of artificial intelligence (AI) to enhance endpoint management solutions. The research explores AI's impact on security, efficiency, and compliance within enterprise environments (R1). Through case studies and empirical analysis, the paper highlights the benefits and challenges of such integrations, offering insights into future developments.
- Categories:
4345 Views
This dataset comprises three degrees of freedom (3 DOF) sensory data and simulation data collected from a Kinova robotic arm. The sensory data includes real-time measurements from the robotic arm’s joint positions, velocities, and torques, providing a detailed account of the arm’s dynamic behavior. The dataset also includes simulated data generated using a high-fidelity physics engine, accurately modeling the Kinova arm’s kinematics and dynamics under various operational scenarios.
- Categories:
108 Views
This dataset has been meticulously curated to evaluate the efficiency of Retrieval-Augmented Generation (RAG) pipelines in both retrieval and generative accuracy, with a particular focus on scenarios involving overlapping contexts. The dataset comprises two primary components: Motor data and Employee data. The Motor dataset includes master data of various motor models along with their corresponding manuals, linked by the motor's model name. Similarly, the Employee dataset encompasses employee master data and associated policy documents, linked by department.
- Categories:
357 Views
This dataset is designed for the reconstruction of images of underground potato tubers using received signal strength (RSS) measurements collected by a ZigBee wireless sensor network. It includes RSS data from sensing areas of various sizes, environments with different layouts, and soils with varying moisture levels. The measurements were obtained from 9 potato tubers of differing sizes and shapes, which were buried in two distinct positions within the sensing area.
- Categories:
190 Views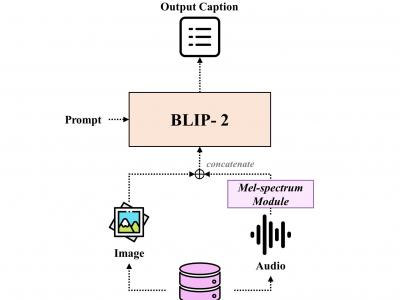
We construct the triple-modality dataset, VGG-sound+, comprising image-text-audio data. Based on VGG-sound, VGG-sound+ consists of 200,000 audio-visual data entries categorized as video data, including metadata label- ing the category of each video clip. We define the image-text-audio triplet modalities of VGG-sound+ as the dataset Di = (Ii , Ti , Ai), where Ii represents an image snap- shot of the video, Ti denotes a textual description of the video, and Ai signifies the audio clip.
- Categories:
676 Views