Artificial Intelligence
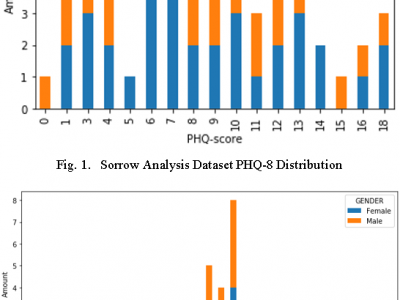
The data collection questionnaire consisted of two sections. One section involved the collection of data via Google Forms questionnaires, and the other involved the collection of WhatsApp voice samples. There were three subsections in the questionnaire section. The first consisted of the individual's basic information, such as email address, name, and identification number. The second was the personal health questionnaire depression scale (PHQ8), which included 8 groups of statements, and the third was the Beck Depression Inventory-II, which contained 21 groups of statements.
- Categories:
 810 Views
810 Views
One of the most consequential creations in the human evolution phase is handwriting. Due to writing, today we are conveying our reflections, making business pacts, rendering an understandable world and making hitherto tasks austerer. Determining gender using offline handwriting is an applied research problem in forensics, psychology, and security applications, and with technological evolution, the need is growing. The general problem of gender detection from handwriting poses many difficulties resulting from interpersonal and intrapersonal differences.
- Categories:
1130 Views
The dataset included 640 patients' vital records, which ranged in age from 18 to 60.
- Categories:
22 Views
The uploaded file is the code of the algorithm FCNEA written in MATLAB.
- Categories:
8 Views
Accurate detection and segmentation of apple trees are crucial in high throughput phenotyping, further guiding apple trees yield or quality management. A LiDAR and a camera were attached to the UAV to acquire RGB information and coordinate information of a whole orchard. The information was integrated by simultaneous localization and mapping network to form a dataset of RGB-colored point clouds. The dataset can be used for methods related to apple detection and segmentation based on point clouds.
- Categories:
656 Views
This dataset is the outcome of an observation on Nigella-satvia germination under cadmium tension and Ascorbic acid based hormonal priming. Cadmium tension levels are 0, 25 and 50 Mm, respectively in this study. Ascorbic acid priming is done under 0, 50,100 and 150 mg/L and each scenario is repeated four times during this study.
- Categories:
127 Views
Leveraging Social Discourse to Identify Check-worthiness of Claims for Fact-checking
- Categories:
8 Views
This dataset contains 3D models of 5 objects and numerous scenes where the objects are placed randomly creating occlusions and cluttered scenes. The 3D models are to be used to find them in the scene (object recognition) and segment them as well.
- Categories:
463 Views
This dataset aims to identify the polarity of tweets—whether they are supportive, oppositional, or neutral—towards the current government. It comprises a total of 26,000 tweets: 15,000 in English and 11,000 in Urdu. These tweets were collected from 80 different political users' accounts to ensure a diverse and comprehensive representation of opinions.
- Categories:
650 Views
42 stimulus pictures are presented separately on the screen in the same sequences for all participants, including landscapes, people, social scenes and composite pictures. The eye tracker records the participants' gaze data on the stimulus pictures. Based on the gaze fixation position and duration, the fixation map could be visualized. We applies a 2-d convolution with a gauss filter on the fixation maps to get the visual heatmaps. The participants consist of schizophrenic patients and healthy controls.
- Categories:
9 Views