Artificial Intelligence

This dataset aims to identify the polarity of tweets—whether they are supportive, oppositional, or neutral—towards the current government. It comprises a total of 26,000 tweets: 15,000 in English and 11,000 in Urdu. These tweets were collected from 80 different political users' accounts to ensure a diverse and comprehensive representation of opinions.
- Categories:
 650 Views
650 Views
42 stimulus pictures are presented separately on the screen in the same sequences for all participants, including landscapes, people, social scenes and composite pictures. The eye tracker records the participants' gaze data on the stimulus pictures. Based on the gaze fixation position and duration, the fixation map could be visualized. We applies a 2-d convolution with a gauss filter on the fixation maps to get the visual heatmaps. The participants consist of schizophrenic patients and healthy controls.
- Categories:
9 Views
We present Vocal92, a multivariate Cappella solo singing and speech audio dataset spanning around 146.73 hours sourced from volunteers. To the best of our knowledge, this is the first dataset of its kind that specifically focuses on a cappella solo singing and speech. Furthermore, we use two current state-of-the-art models to construct the singer recognition baseline system.
- Categories:
33 Views
This dataset provides the high-resolution remote senisng data regarding various coastline scenes.
- Categories:
295 Views
Recently, a limited number of datasets that exist are used to detect errors in the printing process of the 3D printer. Limited datasets lead most researchers to dive into sensor data fault classification.
The dataset is captured and labelled before being fed to the DL model. The image dataset is captured in a time-lapse video mode with a 15-second duration for each printing process. Next, the time-lapse is used to extract around 50 images per video. In total, 2297 images containing four classes are collected.
- Categories:
1867 Views
Retinal Fundus Multi-disease Image Dataset (RFMiD 2.0) is an auxiliary dataset to our previously published dataset. RFMiD 2.0 is a more challenging dataset to research society to develop the computer-based disease diagnosis system. Diabetic Retinopathy, cataracts, and refractive error in the eye are leading disease which causes permanent vision loss more frequently. Therefore, developing an AI-based model to classify these diseases is useful for ophthalmologists. This dataset consists of 860 images of frequently and rarely observed 51 diseases.
- Categories:
3870 Views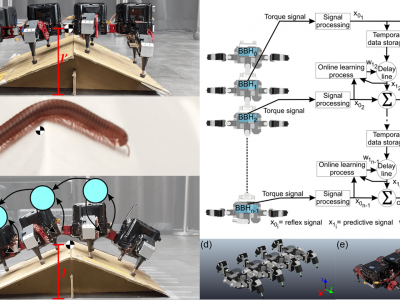
Typically, control strategies for legged robots have been developed to adapt their leg movements to deal with complex terrain. When the legs are extended in search of ground contact to support the robot body, this can result in the center of gravity (CoG) being raised higher from the ground and can lead to unstable locomotion if it deviates from the support polygon. An alternative approach is body adaptation, inspired by millipede/centipede locomotion behavior, which can result in low ground clearance and stable locomotion.
- Categories:
210 Views
Personal assistive devices for rehabilitation will be in increasing demand during the coming decades due to demographic change, i.e., an aging society. Among the elderly population, difficulty in walking is the most common problem. Even though there are commercially available lower limb exoskeleton systems, the coordination between user and device still needs to be improved to achieve versatile personalized gait. To tackle this issue, an advanced EXOskeleton framework for Versatile personalized gaIt generation with a Seamless user-exo interface (called "EXOVIS") is proposed in this study.
- Categories:
405 Views
This dataset, collected from a group of students, contains 505 pages of 10 specific words: a, b, c, d, true, false, correct, incorrect, yes and no; each page in the dataset has 10 rows; each row contains 5 words written by the students. The dataset could help analyze the accuracy and consistency of handwriting for these specific words and in developing and test handwriting recognition systems for these fixed labels. The dataset could be a valuable resource for researchers in the field of education.
- Categories:
86 Views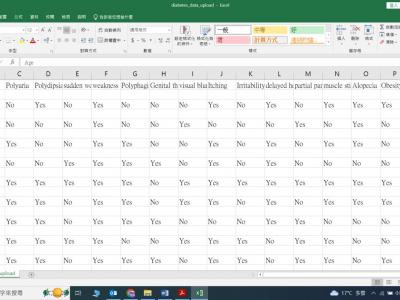
"Early Stage Diabetes Risk Prediction Dataset" from the University of California, Irvine (UCI) machine learning Repository. This data was collected from a direct questionnaire of patients from the Diabetes Hospital in Sylhet, Bangladesh. It contains a total of 520 people with diabetes. Related symptoms are in the reference, of which 320 people have diabetes, and 200 do not.
- Categories:
887 Views