SAD: Sorrow Analysis Dataset
- Citation Author(s):
-
Muhammad Fahreza Alghifari
 (IIUM)
Teddy Surya Gunawan
(IIUM)
Mira Kartiwi
(IIUM)
(IIUM)
Teddy Surya Gunawan
(IIUM)
Mira Kartiwi
(IIUM)
- Submitted by:
- Teddy Surya Gunawan
- Last updated:
- DOI:
- 10.21227/pbkv-6w98
- Data Format:
- Research Article Link:
 878 views
878 views
- Categories:
- Keywords:
Abstract
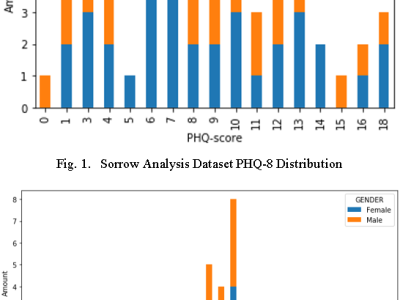
The data collection questionnaire consisted of two sections. One section involved the collection of data via Google Forms questionnaires, and the other involved the collection of WhatsApp voice samples. There were three subsections in the questionnaire section. The first consisted of the individual's basic information, such as email address, name, and identification number. The second was the personal health questionnaire depression scale (PHQ8), which included 8 groups of statements, and the third was the Beck Depression Inventory-II, which contained 21 groups of statements.
The second section consisted of two passages that were to be recorded by the respondent after completing the questionnaire. People were instructed to record their voice samples using WhatsApp's audio recording feature and send them to a specified number for recording purposes. The audience was predominantly Indian and Malay, ranging in age from 19 to 26. In seven days, a total of 64 samples from 30 males and 34 females were collected.
Instructions:
The dataset contains the following:
- Passage 1 contains 64 WAV files.
- Passage 2 contains 64 WAV files.
- SAD_Sorrow Analysis Dataset.xlsx contains speaker, gender, PHQ-9 score, and BDI score.
The total file size is 1.60 GBytes.







