Artificial Intelligence

ALL-IDB (Acute Lymphoblastic Leukemia) Image Database for Image Processing
ALL-IDB dataset comprises of two subsets among them one subset has 260 segmented lymphocytes of them 130 belongs to the leukaemia and the remaining 130 belongs to the non leukaemuia class it requires only classification. second subset has around 108 non segmented blood images that belongs to the leukaemia and non leukaemia groups thus requires segmentation and classification.
- Categories:
 2765 Views
2765 Views
A speech dataset used for fake speech detection. The fake speech are generated by 8 well-known latest deep learning based open-sourced tools and 8 commercial speech synthesis products. All speech are in Chinese or English. It contains more than 127,890 synthetic speech and 14,400 natural speech in English and mandarin Chinese languages.
- Categories:
914 Views
EmoSurv is a dataset containing keystroke data along with emotion labels. Timing and frequency data is recorded while participants are typing free and fixed texts before and after being induced specific emotions. These emotions are: Anger, Happiness, Calmness, Sadness, and Neutral state.
First, data is collected while the participant is in a neutral state. Then, the participant watches an eliciting video. Once the emotion is induced in the participant, he types another fixed and free text.
- Categories:
3474 Views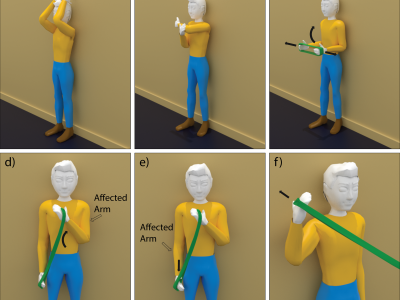
Shoulder Physiotherapy Activity Recognition 9-Axis Dataset (SPARS9x)
Suggested uses of this dataset include performing supervised classification analysis of physiotherapy exercises, or to perform out-of-distribution detection analysis with unlabeled activities of daily living data.
Description:
- Categories:
1716 Views
The dataset provides Abilify Oral user reviews and ratings for drug’s satisfaction, effectiveness, and ease of use on different age groups.
- Categories:
294 Views
Abstract
- Categories:
904 Views
Efficient Privacy-Preserving Federated Learning for Industrial 4.0
- Categories:
282 Views
The dataset is composed of digital signals obtained from a capacitive sensor electrodes that are immersed in water or in oil. Each signal, stored in one row, is composed of 10 consecutive intensity values and a label in the last column. The label is +1 for a water-immersed sensor electrode and -1 for an oil-immersed sensor electrode. This dataset should be used to train a classifier to infer the type of material in which an electrode is immersed in (water or oil), given a sample signal composed of 10 consecutive values.
- Categories:
2304 Views
Optical Character Recognition (OCR) system is used to convert the document images, either printed or handwritten, into its electronic counterpart. But dealing with handwritten texts is much more challenging than printed ones due to erratic writing style of the individuals. Problem becomes more severe when the input image is doctor's prescription. Before feeding such image to the OCR engine, the classification of printed and handwritten texts is a necessity as doctor's prescription contains both handwritten and printed texts which are to be processed separately.
- Categories:
22730 Views
Annotated image dataset of household objects from the RoboFEI@Home team
This data set contains two sets of pictures of household objects, created by the RoboFEI@Home team to develop object detection systems for a domestic robot.
The first data set was created with objects from a local supermarket. Product brands are typical from Brazil. The second data set is composed of objects from the RoboCup@Home 2018 OPL competition.
- Categories:
13793 Views