Artificial Intelligence

The files contain the trained networks (Alexnet, Resnet 18, VGG19, and SRN) for classify the upsampled quadrant data by wavelength.
- Categories:
 40 Views
40 Views
In this paper, the security-aware robust resource allocation in energy harvesting cognitive radio networks is considered with cooperation between two transmitters while there are uncertainties in channel gains and battery energy value. To be specific, the primary access point harvests energy from the green resource and uses time switching protocol to send the energy and data towards the secondary access point (SAP).
- Categories:
529 Views
Source code for the paper "On the Implementation of Behavior Trees in Robotics"
- Categories:
146 Views
The CoVID19-FNIR dataset contains news stories related to CoVID-19 pandemic fact-checked by expert fact-checkers. CoVID19-FNIR is a CoVID-19-specific dataset consisting of fact-checked fake news scraped from Poynter and true news from the verified Twitter handles of news publishers. The data samples were collected from India, The United States of America, and European regions and consist of online posts from social media platforms between February 2020 to June 2020. The dataset went through prepossessing steps that include removing special characters and non-vital information.
- Categories:
6742 Views
The accompanying dataset for the CVSports 2021 paper: DeepDarts: Modeling Keypoints as Objects for Automatic Scoring in Darts using a Single Camera
Paper Abstract:
- Categories:
8063 Views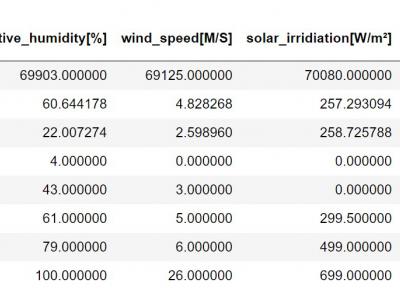
The heating and electricity consumption data are the results of an energy audit program aggregated for multiple load profiles of a residential customer. These profiles include HVAC systems loads, convenience power, elevator, etc. The datasets are gathered between December 2010 and November 2018 with a one-hour timestep resolution, thereby containing 140,160 measurements, half of which is for heat or electricity. In addition to the historical energy consumption values, a concatenation of weather variables is also available.
- Categories:
8143 Views
The DroneDetect dataset consists of 7 different models of popular Unmanned Aerial Systems (UAS) including the new DJI Mavic 2 Air S, DJI Mavic Pro, DJI Mavic Pro 2, DJI Inspire 2, DJI Mavic Mini, DJI Phantom 4 and the Parrot Disco. Recordings were collected using a Nuand BladeRF SDR and using open source software GNURadio. There are 4 subsets of data included in this dataset, the UAS signals in the presence of Bluetooth interference, in the presence of Wi-Fi signals, in the presence of both and with no interference.
- Categories:
15409 Views
The objective of this dataset is the fault diagnosis in diesel engines to assist the predictive maintenance, through the analysis of the variation of the pressure curves inside the cylinders and the torsional vibration response of the crankshaft. Hence a fault simulation model based on a zero-dimensional thermodynamic model was developed. The adopted feature vectors were chosen from the thermodynamic model and obtained from processing signals as pressure and temperature inside the cylinder, as well as, torsional vibration of the engine’s flywheel.
- Categories:
5210 Views
The presence of organisations in Online Social Networks (OSNs) has motivated malicious users to look for attack vectors, which are then used to increase the possibility of carrying out successful attacks and obtaining either private information or access to the organisation. This article hypothesised that organisations have specific languages that their members use in OSNs, which malicious users could potentially use to carry out an impersonation attack.
- Categories:
214 Views
This dataset contains the ontologies and instruments developed in the MIIDAS Project
- Categories:
62 Views