Artificial Intelligence
This dataset includes environmental perception, vehicle motion status, and battery consumption during vehicle operation. The dataset is collected by human operators during the safe and smooth operation of vehicles. By dividing the hazardous areas in the current environment of the vehicle and processing them, a radar map of the hazardous areas is generated; The vehicle motion status section contains the position information (x, y, z) and kinematic information (v, w, a, alpha, beta, gamma) of the vehicle.
- Categories:
 719 Views
719 Views
This study used boots, aircraft, cells, pliers, and guitars from 2D shapes included in the literature as data sets to test modeling success. These 2D shapes, which are mostly not publicly available data sets, form the target curves of IP. In this study, hand drawings with a curved structure were used in modeling, where the success of fitting precision could be better determined.
- Categories:
76 Views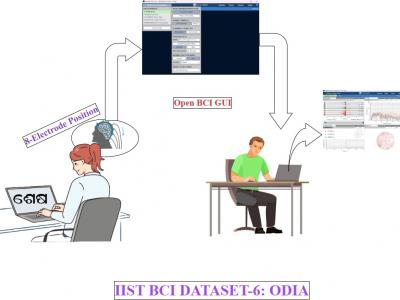
Brain-Computer Interface (BCI) is a technology that enables direct communication between the brain and external devices, typically by interpreting neural signals. BCI-based solutions for neurodegenerative disorders need datasets with patients’ native languages. However, research in BCI lacks insufficient language-specific datasets, as seen in Odia, spoken by 35-40 million individuals in India. To address this gap, we developed an Electroencephalograph (EEG) based BCI dataset featuring EEG signal samples of commonly spoken Odia words.
- Categories:
371 Views
The dataset consists of around 335K real images equally distributed among 7 classes. The classes represent different levels of rain intensity, namely "Clear", "Slanting Heavy Rain", "Vertical Heavy Rain", "Slanting Medium Rain", "Vertical Medium Rain", "Slanting Low Rain", and "Vertical Low Rain". The dataset has been acquired during laboratory experiments and simulates a low-altitude flight. The system consists of a visual odometry system comprising a processing unit and a depth camera, namely an Intel Real Sense D435i.
- Categories:
357 Views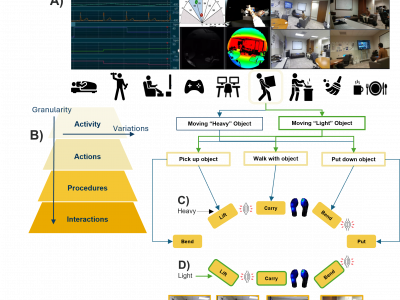
The DARai dataset is a comprehensive multimodal multi-view collection designed to capture daily activities in diverse indoor environments. This dataset incorporates 20 heterogeneous modalities, including environmental sensors, biomechanical measures, and physiological signals, providing a detailed view of human interactions with their surroundings. The recorded activities cover a wide range, such as office work, household chores, personal care, and leisure activities, all set within realistic contexts.
- Categories:
835 Views
Latent fingerprint identification is crucial in forensic science for linking suspects to crime scenes. Latent examiners obtain unique, reliable evidence by revealing hidden prints through advanced techniques. However, latent fingerprints often are partial prints with undesirable characteristics such as noise or distortion. Due to these characteristics, identifying the physical details of a latent fingerprint, known as minutiae, is a complex task. Recent publications found that there are subsets on one minutia in latent fingerprints that, when removed, increase the matching score.
- Categories:
213 Views
Dataset from UCI contains the electricity consumption (in kWh) of 320 customers every 15 minutes from 2011 to 2014. For some customers, their electricity consumption data was recorded starting from a different time, and the data before the first record was marked as 0. As training model requires a starting point for the time series, and different customers have different starting times, some features remain 0 before a certain time point. Using all the data for training would inevitably have a negative impact. Therefore, the data from 2011 is removed and set the starti
- Categories:
672 Views
Existing RGB-T tracking research in general suffers from the challenge of a shortage of training data.
- Categories:
10 Views
The provided data package contains Livox LiDAR scan data from the Calar simulation platform, capturing scenarios in three distinct tunnels, each with various obstacles. The dataset includes LiDAR data recorded at different distances from the sensor, . Additionally, the data encompasses varying numbers of obstacles.
- Categories:
235 Views
The identification of rock fractures in strata is crucial to enhance the intelligence of rock detection. Traditional fracture feature extraction methods suffer from issues such as low accuracy and low processing speed, necessitating the development of more effective approaches. To address this problem, this study proposes a new fracture instance segmentation network called FracSeg. Based on the SOLOv2 framework, we incorporated the Swin Transformer to optimize the backbone network and enhance fracture feature extraction.
- Categories:
229 Views