Artificial Intelligence

This dataset comprises three benchmarks: Digits-5, PACS, anf office_caltech_10. Digits-5 is a set of handwritten digit images sampled from five domains: MNIST, MNIST-M, USPS, SynthDigits, and SVHN. All sample are images of numbers ranging from 0 to 9. PACS is composed of four different datasets, each representing a different visual domain: Photo, Art Painting, Cartoon, and Sketch. It contains 9,944 images, including 1,792 real photos, 2,048 art paintings, 2,344 cartoon images, and 2,760 sketches.
- Categories:
 108 Views
108 Views
Development and Evaluation of a Novel GPT-like Conditional Molecule Generator
This study presents the development and evaluation of a novel GPT-like conditional molecule generator designed to optimize the synthesis of chemical compounds with desirable properties. The model incorporates six pivotal physicochemical properties as conditions:
- Categories:
56 Views
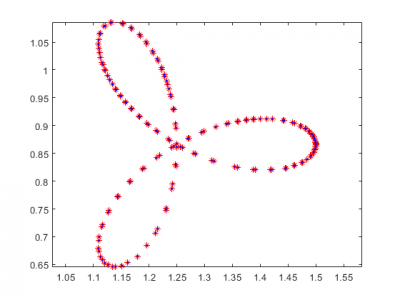
Dynamic nonlinear equations (DNEs) are essential for modeling complex systems in various fields due to their ability to capture real-world phenomena. However, the solution of DNEs presents significant challenges, especially in industrial settings where periodic noise often compromises solution fidelity. To tackle this challenge, we propose a novel approach called Periodic Noise Suppression Neural Dynamic (PNSND), which leverages the gradient descent approach and incorporates velocity compensation to overcome the limitations of the traditional Gradient Neural Dynamic (GND) model.
- Categories:
219 Views
This paper presents a comparative study of sampling methods within the FedHome framework, designed for personalized in-home health monitoring. FedHome leverages federated learning (FL) and generative convolutional autoencoders (GCAE) to train models on decentralized edge devices while prioritizing data privacy. A notable challenge in this domain is the class imbalance in health data, where critical events such as falls are underrepresented, adversely affecting model performance.
- Categories:
159 Views
Wild-SHARD presents a novel Human Activity Recognition (HAR) dataset collected in an uncontrolled, real-world (wild) environment to address the limitations of existing datasets, which often need more non-simulated data. Our dataset comprises a time series of Activities of Daily Living (ADLs) captured using multiple smartphone models such as Samsung Galaxy F62, Samsung Galaxy A30s, Poco X2, One Plus 9 Pro and many more. These devices enhance data variability and robustness with their varied sensor manufacturers.
- Categories:
464 Views
Hand contact data, reflecting the intricate behaviours of human hands during object operation, exhibits significant potential for analysing hand operation patterns to guide the design of hand-related sensors and robots, and predicting object properties. However, these potential applications are hindered by the constraints of low resolution and incomplete capture of the hand contact data.
- Categories:
200 Views
IRIC method's data and code are available at this URL.
These data links contain publicly available datasets that can be downloaded directly from their website. Our research on IRIC has validated the performance of the model through these publicly available datasets. Please continue to pay attention.
These data mainly include Emergency Event Data (ALARM) and Education Dataset (Junyi), which can be used for research in causal structure learning, knowledge tracking, and other areas.
- Categories:
55 Views
This is the collection of the Ecuadorian Traffic Officer Detection Dataset. This can be used mainly on Traffic Officer detection projects using YOLO. Dataset is in YOLO format. There are 1862 total images in this dataset fully annotated using Roboflow Labeling tool. Dataset is split as follow, 1734 images for training, 81 images for validation and 47 images for testing. Dataset is annotated only as one class-Traffic Officer (EMOV). The dataset produced a Mean Average Precision(mAP) of 96.4 % using YOLOv3m, 99.0 % using YOLOv5x and 98.10 % using YOLOv8x.
- Categories:
350 Views
This dataset is shared for capacitor C and ESR estimation using convolution neural network. The dataset is collected in a experimental modular moultilevel converter, which includes the capacitor voltage at low and medium frequency band, and the arm current. Wavelet transform is used to transfer the time series data to images, which present the inherent data features to image patterns. In a degraded capacitor, the C decreases and the ESR increases, which result in different image patterns.
- Categories:
242 Views