Artificial Intelligence

文件名为中国车牌号,图像为BMP格式
- Categories:
 143 Views
143 Views
This dataset was prepared to aid in the creation of a machine learning algorithm that would classify the white blood cells in thin blood smears of juvenile Visayan warty pigs. The creation of this dataset was deemed imperative because of the limited availability of blood smear images collected from the critically endangered species on the internet. The dataset contains 3,457 images of various types of white blood cells (JPEG) with accompanying cell type labels (XLSX).
- Categories:
3579 Views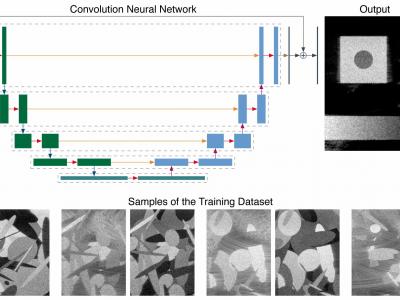
This repository contains the data related to the paper “CNN-Based Image Reconstruction Method for Ultrafast Ultrasound Imaging” (10.1109/TUFFC.2021.3131383). It contains multiple datasets used for training and testing, as well as the trained models and results (predictions and metrics). In particular, it contains a large-scale simulated training dataset composed of 31000 images for the three different imaging configuration considered (i.e., low quality, high quality, and ultrahigh quality).
- Categories:
3498 Views
EEG consists of collecting information from brain activity in the form of electrical voltage. Epileptic Seizure prediction and detection is a major sought after research nowadays. This dataset contains data from 11 patients of whom seizures are observed in EEG for 2 patients.
The total duration of seizures is 170 seconds. The number of channels is 16 and data is collected at 256Hz sampling rate.
The final dataset files in .csv format contain 87040 rows x 17 columns,
- Categories:
3396 Views
Automated driving in public traffic still faces many technical and legal challenges. However, automating vehicles at low speeds in controlled industrial environments is already achievable today. A reliable obstacle detection is mandatory to prevent accidents. Recent advances in convolutional neural network-based algorithms have made it conceivable to replace distance measuring laser scanners with common monocameras.
- Categories:
796 Views
Our experimental data come from a city commercial bank in China. These data belong to the bank’s private database. The original data set has 67 attributes and a total of 29,723 loan samples.
Normal
0
7.8 磅
0
2
false
false
false
EN-US
ZH-CN
X-NONE
- Categories:
333 Views
Preprocessed dataset
- Categories:
250 Views
A Dynamic Multi-Objective Evolutionary Algorithm
- Categories:
300 Views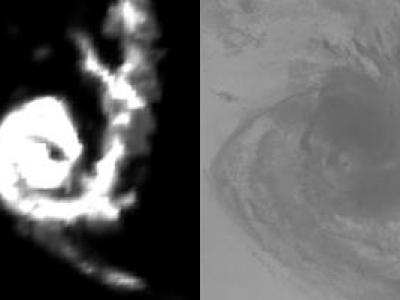
This dataset is the supporting dataset for the paper "Simulating tropical cyclone passive microwave rainfall imagery using infrared imagery via generative adversarial networks". The dataset contains infrared images as well as passive microwave rainfall images, and they are paired.
- Categories:
771 Views
This dataset is related to dog activity and is sensor data.
- Categories:
911 Views