Artificial Intelligence

The dataset provides textures generated from elliptical cosine and sinc fractional Brownian field models.
- Categories:
 102 Views
102 Views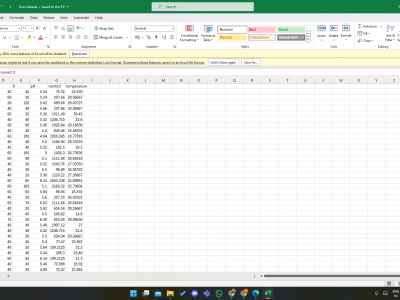
This dataset is composed by both real and sythetic images of power transmission lines, which can be fed to deep neural networks training and applied to line's inspection task. The images are divided into three distinct classes, representing power lines with different geometric properties. The real world acquired images were labeled as "circuito_real" (real circuit), while the synthetic ones were identified as "circuito_simples" (simple circuit) or "circuito_duplo" (double circuit). There are 348 total images for each class, 232 inteded for training and 116 aimed for validation/testing.
- Categories:
3866 Views
The code and dataset for multimodal unknown surface material classification.
- Categories:
176 Views
The crime rate is increasing at a high rate in India. Terrorist attacks like Mumbai 26/11, Pulwama attack, Pune German Beckary attacks have created terrific fear amongst Indian Society. Video analytics plays a significant role in detecting and predicting such suspicious human activities using deep learning models It will help in reducing the increasing crime rate by preventing treacherous actions. Video analytics analyzes the video content and adds brains to eyes i.e. analytics to the camera. It extracts contents from the video by monitoring the video in real-time.
- Categories:
2568 Views
this is a test
- Categories:
332 Views
Decision variables of the best run for each algorithm
- Categories:
48 Views
Any work using this dataset should cite the following paper:
- Categories:
10096 Views
Dataset for handwriting digit layout generation。
- Categories:
132 Views
Any work using this dataset should cite the following paper:
- Categories:
1887 Views
The video data set was obtained from the Mental Health Center of Renmin Hospital of Wuhan University, it includes 128 children and the video records the behavior of each subject (mainly upper body movements) during clinical intelligence evaluation. The ratio of training set, validation set and test set is 7:1:2.
- Categories:
232 Views