Machine Learning

Brain tumors are among the most severe and life-threatening conditions affecting both children and adults. They constitute approximately 85-90% of all primary Central Nervous System (CNS) tumors, with an estimated 11,700 new cases diagnosed annually. The 5-year survival rate for individuals with malignant brain or CNS tumors is alarmingly low, at 34% for men and 36% for women. Brain tumors are categorized into various types, including benign, malignant, and pituitary tumors.
- Categories:
 94 Views
94 Views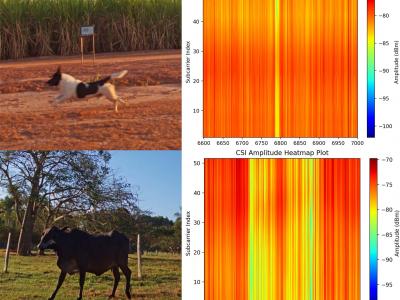
This dataset is shared as part of the paper Towards scalable and low-cost WiFi sensing: preventing animal-vehicle collisions on rural roads, submitted to the IEEE Internet of Things Journal (IoT-J). It contains Wi-Fi Channel State Information (CSI) data from roadway crossings of small and large animals, persons and vehicles in rural environments.
- Categories:
74 Views
This dataset is the rent price for Kuala Lumpur and its neighborhood obtained from mudah.my in July 2024. The raw data is unprocessed and contains the original description of the house, the details in JSON format, the rent price, and the period.
This dataset is ideal for making rent price forecasts and exploring in depth what factors influence rent prices.
- Categories:
178 Views
BoardData is constructed from development board data provided by ST. These development boards are primarily utilized for function demonstration and platform development of STM32 series microcontrollers. They incorporate a suite of common sub-circuit modules for electronic devices, including interface modules, digital-to-analog and analog-to-digital converter modules, memory modules, comparators, touch modules, display modules, switch arrays, among others. Consequently, these boards exhibit a high degree of consistency with real PCB circuits.
- Categories:
16 Views
Memes (photos with text) for fine-tuning AGI. Training in recognizing and generating memes, jokes, mockery, trolling, emotions in foreign languages. This is a demo sample (will be expanded) before data expansion. Hundreds of variants were created for each meme. Meme text without using the expanded data set is difficult enough for AGI to correctly recognize emotions. With the data set expansion, the accuracy increases significantly.
- Categories:
76 Views
This data approach student achievement in secondary education of two Portuguese schools. The data attributes include student grades, demographic, social and school related features) and it was collected by using school reports and questionnaires. Two datasets are provided regarding the performance in two distinct subjects: Mathematics (mat) and Portuguese language (por). In [Cortez and Silva, 2008], the two datasets were modeled under binary/five-level classification and regression tasks. Important note: the target attribute G3 has a strong correlation with attributes G2 and G1.
- Categories:
28 Views
RSHIP137 is a self-built remote sensing dataset of ships, consisting of 119,330 images across 137 categories. The size of each image varies, with the largest having dimensions of 182x699 and the smallest being 7x11. The distribution of categories is highly imbalanced, with the most frequent category being "Barge," which contains 31,466 images, and the least frequent category being "901-fast combat support ship," with only 15 images.
- Categories:
26 Views
Mirror arrays have been applied to indoor visible light communication (VLC) as a passive the reconfigurable intelligent surface (RIS) which has no signal processing to solve the problem of indoor visible light line-of-sight obstruction, however, after channel modeling, it is found that the reflected channel in this scenario has a serious multipath effect, to this end, we introduce deep learning techniques into channel estimation of VLC systems with mirror arrays for the first time, and propose a hybrid new model of Transformer and the bidirectional longshort-term memory model (Transformer-B
- Categories:
18 Views
This is a pump fillage time series data set, consisting of 8 time series. The data is sourced from actual production data during the operational process of an oil field. It includes data from 8 oil wells, with measurements collected every half hour between July 22, 2022, and August 16, 2022. The pump fillage is extracted from the operational process of an oil field. The pump fillage data for each well is sorted in chronological order to obtain the pump fillage time series for each well. The data set had varying numbers of cards due to potential communication issues, rangin
- Categories:
17 Views
This is a pump fillage time series data set, consisting of 8 time series. The data is sourced from actual production data during the operational process of an oil field. It includes data from 8 oil wells, with measurements collected every half hour between July 22, 2022, and August 16, 2022. The pump fillage is extracted from the operational process of an oil field. The pump fillage data for each well is sorted in chronological order to obtain the pump fillage time series for each well. The data set had varying numbers of cards due to potential communication issues, rangin
- Categories:
14 Views