Machine Learning

Industrial cyber-physical systems (ICPS), which is the backbone of Industry 4.0, are the result of adapting emerging information communication technologies (ICT) to the industrial control systems (ICS). ICPS utilize autonomous robotic arms to accomplish manufacturing tasks. These arms follow a certain predetermined trajectory during the task.
In this dataset, we present four files generated from a setup that contains two Universal Robot UR3e collaborative robotic arms:
- Categories:
 1055 Views
1055 Views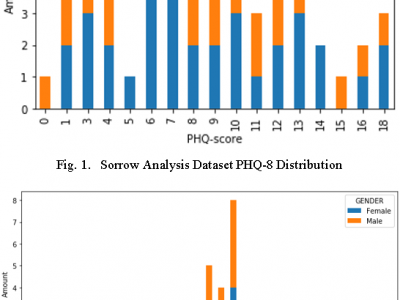
The data collection questionnaire consisted of two sections. One section involved the collection of data via Google Forms questionnaires, and the other involved the collection of WhatsApp voice samples. There were three subsections in the questionnaire section. The first consisted of the individual's basic information, such as email address, name, and identification number. The second was the personal health questionnaire depression scale (PHQ8), which included 8 groups of statements, and the third was the Beck Depression Inventory-II, which contained 21 groups of statements.
- Categories:
824 Views
One of the most consequential creations in the human evolution phase is handwriting. Due to writing, today we are conveying our reflections, making business pacts, rendering an understandable world and making hitherto tasks austerer. Determining gender using offline handwriting is an applied research problem in forensics, psychology, and security applications, and with technological evolution, the need is growing. The general problem of gender detection from handwriting poses many difficulties resulting from interpersonal and intrapersonal differences.
- Categories:
1151 Views
The dataset included 640 patients' vital records, which ranged in age from 18 to 60.
- Categories:
25 Views
The dataset contains performance values, Area Under the ROC Curve (AUC) and Average Precision (AP), of popular anomaly detection (AD) algorithms taken over a set of 9k AD benchmark datasets.
Datasets were initially published with the following paper:
Kandanaarachchi, S., Muñoz, M. A., Hyndman, R. J., & Smith-Miles, K. (2020). On normalization and algorithm selection for unsupervised outlier detection. Data Mining and Knowledge Discovery, 34(2), 309-354.
- Categories:
396 Views
In this paper, a novel time-constrained global and local nonlinear analytic stationary subspace analysis (Tc-GLNASSA) is proposed to enhance blast furnace ironmaking process (BFIP) monitoring. Although existing analytic stationary subspace analysis method has been available for deriving process consistent relationships. However, the presence of complex nonlinear, periodic nonstationary and time-varying smelting conditions renders the satisfactory estimation of stationary projections unattainable.
- Categories:
170 Views
This dataset contains one month of the binary activity of the 4060 urban IoT nodes. Each record in the dataset presents the node ID, the time stamp, the location of the IoT node in latitude and longitude, and also the binary activity of the IoT node. The main purpose of this dataset is to be used as part of distributed denial of service (DDoS) attack research.
- Categories:
616 Views
Accurate detection and segmentation of apple trees are crucial in high throughput phenotyping, further guiding apple trees yield or quality management. A LiDAR and a camera were attached to the UAV to acquire RGB information and coordinate information of a whole orchard. The information was integrated by simultaneous localization and mapping network to form a dataset of RGB-colored point clouds. The dataset can be used for methods related to apple detection and segmentation based on point clouds.
- Categories:
698 Views
The Zip file contain the videos of the indoor/outdoor test, as well as the data logged during the flights and the CAD files to replicate the balloon systems.
- Categories:
162 Views
Data preprocessing is a fundamental stage in deep learning modeling and serves as the cornerstone of reliable data analytics. These deep learning models require significant amounts of training data to be effective, with small datasets often resulting in overfitting and poor performance on large datasets. One solution to this problem is parallelization in data modeling, which allows the model to fit the training data more effectively, leading to higher accuracy on large data sets and higher performance overall.
- Categories:
103 Views