Machine Learning
The IARPA Space-Based Machine Automated Recognition Technique (SMART) program was one of the first large-scale research program to advance the state of the art for automatically detecting, characterizing, and monitoring large-scale anthropogenic activity in global scale, multi-source, heterogeneous satellite imagery. The program leveraged and advanced the latest techniques in artificial intelligence (AI), computer vision (CV), and machine learning (ML) applied to geospatial applications.
- Categories:
 150 Views
150 Views
The Dash Cam Video Dataset is a comprehensive collection of real-world road footage captured across various Indian roads, focusing on lane conditions and traffic dynamics. Indian roads are often characterized by inconsistent lane markings, unstructured traffic flow, and frequent obstructions, making lane detection and traffic identification a challenging task for autonomous vehicle systems.
- Categories:
428 Views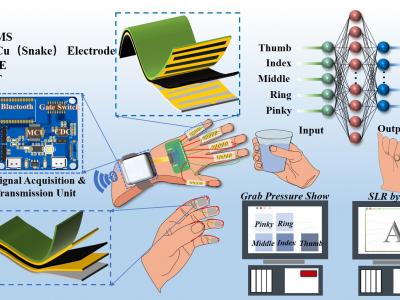
Flexible tactile sensors have attracted significant interest in robotics, medical monitoring, and wearable devices. This paper presents a capacitive flexible tactile sensor that employs a nickel carbonyl powder (NCP)-silicone rubber (SR) composite for pressure and bending sensing, fabricated using magnetic field curing. The performance of the sensor is evaluated independently for pressure and bending sensing, including sensitivity, response time, repeatability, and cyclic stability.
- Categories:
244 Views
The BNS (Bharatiya Nyay Sanhita) dataset is a comprehensive collection of legal texts which was web-scraped.. It consists of chapters and their respective sections, capturing detailed legal content relevant to the recently introduced BNS framework in India. This dataset was gathered using a Python-based web scraping script leveraging Selenium WebDriver, ensuring accuracy and completeness. Available in CSV formats, the dataset facilitates ease of access for legal research, natural language processing (NLP) tasks, and AI-based legal assistance applications.
- Categories:
116 Views
The PhishFOE Dataset is a comprehensive dataset designed for phishing URL detection using machine learning techniques. The dataset contains 101,083 URLs, with labeled features extracted from both the URL structure and HTML content of webpages. It provides insights into key characteristics that distinguish phishing websites from legitimate ones.
-
Total Samples: 101,063
-
Label:
0for Legitimate,1for Phishing
- Categories:
83 Views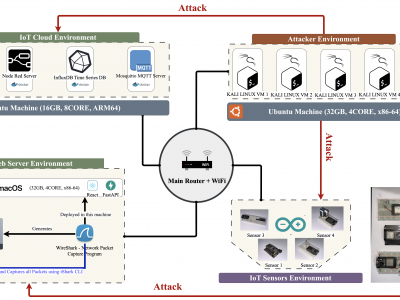
This paper presents an enhanced methodology for network anomaly detection in Industrial IoT (IIoT) systems using advanced data aggregation and Mutual Information (MI)-based feature selection. The focus is on transforming raw network traffic into meaningful, aggregated forms that capture crucial temporal and statistical patterns. A refined set of 150 features including unique IP counts, TCP acknowledgment patterns, and ICMP sequence ratios was identified using MI to enhance detection accuracy.
- Categories:
449 Views
This dataset is used for machine learning. And the data set is collected in different micro-environments. In this project, ExpoM-RF 4 is used to measure the electric field strength. Four different typs of micro-environments are selected which are urban (6 high population density areas in Kuala Lumpur), suburban (7 low population density areas in Cyberjaya), park (3 park areas) and one indoor micro-environment. From the measurement campaigns, three machine learning (ML) techniques are simulated to model the Electric Field Strength in each micro-environment.
- Categories:
62 Views
This dataset comprises 2 million synthetic samples generated using the Variational Autoencoder-Generative Adversarial Network (VAE-GAN) technique. The dataset is designed to facilitate cardiovascular disease prediction through various demographic, physical, and health-related attributes. It contains essential physiological and behavioral indicators that contribute to cardiovascular health.
Dataset Description The dataset consists of the following features:
- Categories:
336 Views
This dataset comprises 2 million synthetic samples generated using the Variational Autoencoder-Generative Adversarial Network (VAE-GAN) technique. The dataset is designed to facilitate cardiovascular disease prediction through various demographic, physical, and health-related attributes. It contains essential physiological and behavioral indicators that contribute to cardiovascular health.
Dataset Description The dataset consists of the following features:
- Categories:
488 Views
LIVE-Viasat Real-World Satellite QoE Database contains 179 videos from real-world streaming, encompassing a range of distortions. Enhanced by a study with 54 participants providing detailed QoE feedback, our work not only provides a rich analysis of the determinants of subjective QoE but also delves into how various streaming impairments influence user behavior, thereby offering a more holistic understanding of user satisfaction.
- Categories:
13 Views