Machine Learning

The development of metaverses and virtual worlds on various platforms, including mobile devices, has led to the growth of applications in virtual reality (VR) and augmented reality (AR) in recent years. This application growth is paralleled by a growth of interest in analyzing and understanding AR/VR applications from security and performance standpoints. Despite this growing interest, benchmark datasets are lacking to facilitate this research pursuit.
- Categories:
 347 Views
347 Views
This is the pest image dataset. With this data set at hand, scientists or software engineers may create programs capable of recognizing when creatures harm farm produce. This breadth extends not only across different plants but also covers many types of bugs like aphids, leafhoppers, beetles , caterpillars etcetera providing a large diverse pool from which one can train models designed to detect pests. Arranging photos by pest species makes it easy for people looking into them understand what they should expect find.
- Categories:
1355 Views
The original data includes structured and unstructured impact factors. The structured impact factors are from the wind database, and the unstructured impact factors are from the official Baidu Index website, obtained through the Python 3.8 crawler.
The preprocessed data is filled with the original data after excluding outliers and some missing values, which is used to screen influencing factors.
- Categories:
134 Views
The "CloudPatch-7 Hyperspectral Dataset" comprises a manually curated collection of hyperspectral images, focused on pixel classification of atmospheric cloud classes. This labeled dataset features 380 patches, each a 50x50 pixel grid, derived from 28 larger, unlabeled parent images approximately 4402-by-1600 pixels in size. Captured using the Resonon PIKA XC2 camera, these images span 462 spectral bands from 400 to 1000 nm.
- Categories:
509 Views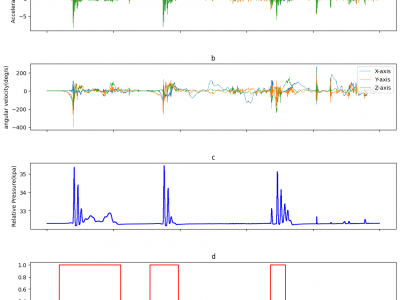
The data was collected by outfitting one of the players with the experimental balloon, which incorporated the embedded circuit and sensors. The sensors positioned at the top-right to the player within the bubble balloon, where a player stand inside. The sensors' data were collected at specific sampling frequencies (Accelerometer: 1000Hz, Gyroscope: 1000Hz, and Pressure: 40Hz). The experiment was conducted involving five different players. This approach allowed for the inclusion of diverse data samples, taking into account variations in player metrics, movements, and gameplay dynamics.
- Categories:
178 Views
Early detection of kidney illness can be achieved by training machine learning algorithms to discover patterns in patient data, such as imaging, test results, and medical history. This will enable rapid diagnosis and start of treatment regimens, which can improve patient outcomes. With 98.97% accuracy in CKD detection, the suggested TrioNet with KNN imputer and SMOTE fared better than other models. This comprehensive research highlights the model's potential as a useful tool in the diagnosis of chronic kidney disease (CKD) and highlights its capabilities.
- Categories:
1001 Views
The Chattel Text was obtained by personnel on-site through the camera in the perception cap due to the lack of open source data. Among them, the Chattel Text dataset is 828 sheets. The Chattel Text dataset in this paper is labeled by labelImg to calibrate the text box and get the labeled document. The label document contains 8 numbers and a text, where the 8 numbers are the horizontal and vertical coordinates of the four vertices of the rectangular text box in the picture. Due to the randomized environment, some of the texts in the picture will be skewed and other characteristics.
- Categories:
136 Views
Flow to image conversion is a pivotal preprocessing step in intrusion detection systems (IDS) where the representation of network flow data significantly influences classifier performance. In this study, we explore the effects of three distinct methods of transforming flow data into images on classifier performance.
- Categories:
228 Views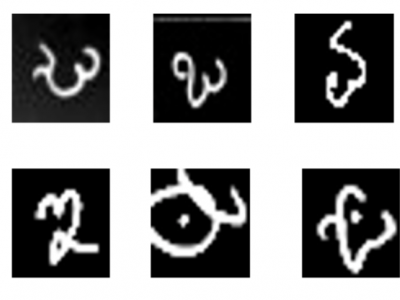
One of the Dravidian language spoken majorly by 60 million people in and around Karnataka state of India is known as Kannada. It is one among 22 scheduled languages of India. Kannada langauge is written in Kannada scriptwhich has its traces back from kadamba script (325-550 AD). There are many languages which were used centuries back and aren’t being used currently whereas Kannada is one such language which is used even today for writing official documents and are being taught at schools which means it is going to be for many years.
- Categories:
173 Views
This paper presents a dataset of brain Electroencephalogram (EEG) signals created when Malayalam vowels and consonants are spoken. The dataset was created by capturing EEG signals utilizing the OpenBCI Cyton device while a volunteer spoke Malayalam vowels and consonants. It includes recordings obtained from both sub-vocal and vocal. The creation of this dataset aims to support individuals who speak Malayalam and suffer from neurodegenerative diseases.
- Categories:
2558 Views