Machine Learning

This dataset supports the LookCursor AI project, which implements eye-tracking-based cursor control using OpenCV and Dlib. The primary file included is shape_predictor_68_face_landmarks.dat, a pre-trained model used to detect and map 68 facial landmarks essential for tracking eye movements. The dataset enables accurate facial feature detection, which is critical for cursor movement based on eye gaze.
- Categories:
 134 Views
134 Views
The AMD3IR dataset is a large-scale collection of Shortwave Infrared (SWIR) and Longwave Infrared (LWIR) images, designed to advance the ongoing research in the field of drone detection and tracking. It efficiently addresses key challenges such as detecting and distinguishing small airborne objects, differentiating drones from background clutter, and overcoming visibility limitations present in conventional imaging. The dataset comprises 20,865 SWIR images with 24,994 annotated drones and 8,696 LWIR images with 10,400 annotated drones, featuring various UAV models.
- Categories:
588 Views
A significant challenge in racing-related research is the lack of publicly available datasets containing raw images with corresponding annotations for the downstream task. In this paper, we introduce RoRaTrack, a novel dataset that contains annotated multi-camera image data from racing scenarios for track detection. The data is collected on a Dallara AV-21 at a racing circuit in Indiana, in collaboration with the Indy Autonomous Challenge (IAC).
- Categories:
29 Views
Vehicle-to-everything (V2X) collaborative perception has emerged as a promising solution to address the limitations of single-vehicle perception systems.
- Categories:
249 Views
EEG signals in the NMT-5k dataset were captured using a 21-channel setup following the 10/20 electrode placement system, maintaining a sampling rate of 200 Hz. Data collection was conducted using the KT88-2400 system from Contec Medical Systems.
- Categories:
102 Views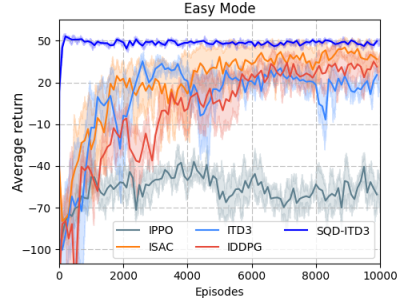
The proposed method is rigorously evaluated against several state-of-the-art algorithms, including ISAC, ITD3, IPPO, and IDDPG, to ensure a comprehensive performance analysis. The experimental data, which is publicly available [here], provides detailed insights into the training and evaluation processes of each algorithm.
- Categories:
157 Views
Dataset Description
This dataset is designed for analyzing and predicting comeback victories in Multiplayer Online Battle Arena (MOBA) games. It is derived from match data where an objective bounty mechanism was active, providing features that highlight differences between teams with and without the bounty advantage. The dataset is ideal for machine learning tasks, such as binary classification and feature importance analysis, and it enables researchers and analysts to explore factors influencing comeback scenarios in competitive gaming.
Dataset Contents:
- Categories:
91 Views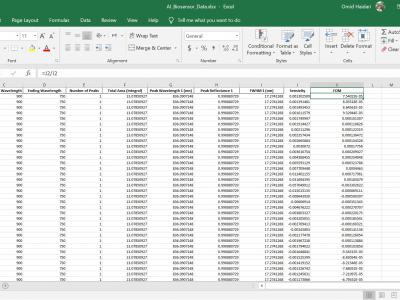
Comprehensive dataset (5000 spectra) of simulated grating biosensor reflections in Excel format. Generated via Lumerical FDTD, it includes 11 parameters (thickness, RI, peak wavelength, FWHM, reflectance, etc.). It is ideal for data visualization, sensor response exploration, and AI/ML benchmarking. The full dataset in Excel format is coming soon! Follow this repository to be notified when it's released. In the meantime, feel free to browse the README for more information about the project.
- Categories:
327 Views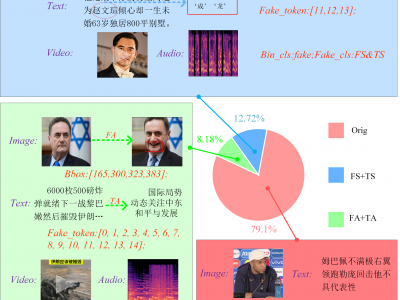
DLSF is the first dedicated dataset for Text-Image Synchronization Forgery (TISF) in multimodal media. The source data for this dataset is scraped from the Chinese news aggregation platform, Toutiao. This dataset includes extensive text, image, and audio-video data from news articles involving politicians and celebrities, featuring samples of both entity-level and attribute-level TISF. It provides comprehensive annotations, including labels for text-image authenticity, types of TISF, image forgery regions, and text forgery tokens.
- Categories:
109 Views
This dataset provides a comprehensive record of wind power generation and its relationship with oceanic-atmospheric indices, facilitating advanced forecasting and analytical research in renewable energy. The dataset comprises 12 input parameters, including average wind speed, which serves as a crucial predictor, while wind power generation acts as the output variable.
- Categories:
169 Views