Image Processing
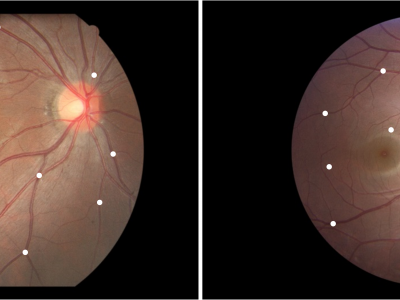
Fundus Image Myopia Development (FIMD) dataset contains 70 retinal image pairs, in which, there is obvious myopia development between each pair of images. In addition, each pair of retinal images has a large overlap area, and there is no other retinopathy. In order to perform a reliable quantitative evaluation of registration results, we follow the annotation method of Fundus Image Registration (FIRE) dataset [1] to label control points between the pair of retinal images with the help of experienced ophthalmologists. Each image pair is labeled with
- Categories:
 463 Views
463 Views
This dataset contains the Supplementary Information of the article "Discovering Mathematical Patterns Behind HIV-1 Genetic Recombination: a new methodology to identify viral features" (Manuscript DOI: 10.1109/ACCESS.2023.3311752).
- Categories:
307 Views
SYPHAXAR dataset is a dataset for Arabic text detection in the wild. It was collected from Tunisia in “Sfax” city, the second largest Tunisian city after the capital. A total of 3078 images were gathered through manual collection one by one, with each image energizing text detection challenges in nature according to real existing complexity of 15 different routes along with ring roads, intersections and roundabouts. These annotated images consist of more than 31000 objects, each of which is enclosed within a bounding box.
- Categories:
249 Views
Point cloud streaming has recently attracted research attention as it has the potential to provide six degrees of freedom movement, which is essential for truly immersive media. The transmission of point clouds requires high-bandwidth connections, and adaptive streaming is a promising solution to cope with fluctuating bandwidth conditions. Thus, understanding the impact of different factors in adaptive streaming on the Quality of Experience (QoE) becomes fundamental. Point clouds have been evaluated in Virtual Reality (VR), where viewers are completely immersed in a virtual environment.
- Categories:
112 Views

The "Paddy Field Dataset Captured in Palakkad District, Kerala, India" is a comprehensive collection of geospatial and attribute data specifically focused on paddy cultivation within the Palakkad district of the Kerala state in India. This dataset encompasses a wide range of information related to paddy fields, including their spatial distribution, size, crop varieties cultivated, land management practices, and relevant contextual factors. Geographic Information System (GIS) technology has captured accurate geospatial coordinates, enabling precise mapping and analysis.
- Categories:
1011 Views
The "Paddy Disease Dataset" represents a comprehensive collection of data related to various diseases commonly found in paddy crops. Paddy, or rice, is a staple crop crucial for global food security. However, paddy crops are susceptible to a range of diseases that can significantly impact yield and quality. This dataset encompasses a diverse array of disease-related information, including disease types, symptoms, geographical distribution, severity levels, and potential management strategies.
- Categories:
667 Views
We used Sentinel-2 images to create the dataset In order to estimate sequestered carbon in the above-ground forest Biomass. Moreover, fieldwork was completed to gather related forest biomass volume. The clipped image has a size of 1115 × 955 pixels and consists of bands 3, 4, and 8, which correspond to green, red, and near-infrared.
- Categories:
1079 Views
Real-world images often encompass embedded texts that adhere to disparate disciplines like business, education, and amusement, to name a few. Such images are graphically rich in terms of font attributes, color distribution, foreground-background similarity, and component organization. This aggravates the difficulty of recognizing texts from these images. Such characteristics are very prominent in the case of movie posters. One of the first pieces of information on movie posters is the title.
- Categories:
244 Views
Videos contain a high volume of texts and are broadcasted via different sources, such as television, the internet, etc. Since optical character recognition (OCR) engines are script-dependent, script identification is the precursor for them. Depending on the video sources, identification of video scripts is not trivial since we have difficult issues, such as low resolution, complex background, noise, blur effects, etc. In this work, a deep learning-based system named as LWSINet: LightWeight Script Identification Network (6-layered CNN) is proposed to identify the video scripts.
- Categories:
126 Views