NLP

The data is derived from 22,898 comments on driverless and human driving obtained by crawler technology on China's Weibo and XiaoHongshu platforms from May 1 to August 31, 2024. The main data formats are xlsx, py, txt, json and so on. The files in py format are script files, which are used to process data. The dataset was eventually used for topic mining, sentiment analysis, and more on Chinese users' comments on driverless and human driving.
- Categories:
 31 Views
31 Views
This dataset is designed for the classification of textual transcriptions of spoken conversations in Shanghai dialect and Mandarin Chinese. It consists of high-quality, manually transcribed texts from natural dialogues, annotated with corresponding language labels (Shanghai dialect: 1, Mandarin: 0).
- Categories:
10 Views
Legal analysis utilizing natural language processing and machine learning technologies is a difficult undertaking that has recently sparked the interest of many academics and industries. Using a human-annotated dataset summarized into colloquial Thai from Supreme Court decisions, this work investigates a different combination of NLP, ML, and rule-based techniques for accurate legal case analysis as per Thai law, especially property-related offences, with the intuition to imitate the lawyer's cognitive process.
- Categories:
21 Views
The process of allocating the intestate inheritance among the statutory heirs is sophisticated yet occurs regularly. Many scholars have attempted to develop automated allocation systems to tackle this High task. However, most amply existing systems rely on conventional form-based input, which may overwhelm the general users. Furthermore, no existing system concerning intestate inheritance allocation according to the Civil and Commercial Code of Thailand is publicly available.
- Categories:
29 Views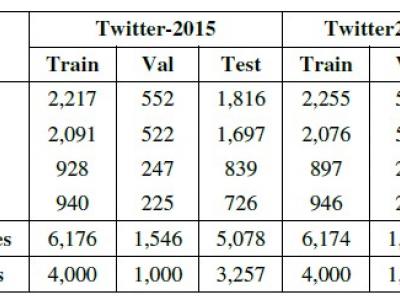
<p>The <strong>Twitter2015-Urdu Dataset</strong> is a multimodal resource designed to advance Multimodal Named Entity Recognition (MNER) research in Urdu, a low-resource language. It adapts the widely used Twitter2015 English dataset with culturally grounded annotations tailored to Urdu's unique linguistic complexities.
- Categories:
25 Views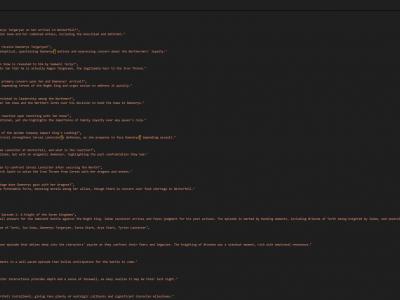
DragonVerseQA is an open-domain and long-form Over-The-Top (OTT) Question-Answering (QA) dataset specifically oriented to the fantasy universe of "The House of the Dragon" and "Game Of Thrones" TV series. The curated dataset combines full episode summaries sourced from HBO and fandom wiki websites, user reviews from sources like IMDb and Rotten Tomatoes, and high-quality, open-domain, legally admissible sources, and structured data from repositories like WikiData into one dataset.
- Categories:
151 Views
Please cite the following paper when using this dataset:
Vanessa Su and Nirmalya Thakur, “COVID-19 on YouTube: A Data-Driven Analysis of Sentiment, Toxicity, and Content Recommendations”, Proceedings of the IEEE 15th Annual Computing and Communication Workshop and Conference 2025, Las Vegas, USA, Jan 06-08, 2025 (Paper accepted for publication, Preprint: https://arxiv.org/abs/2412.17180).
Abstract:
- Categories:
154 Views
This dataset comprises a comprehensive collection of PubMed abstracts and associated metadata focusing on the topic of multiple sclerosis (MS) in relation to social determinants and environmental factors, spanning publications from January 1, 2018, to November 15, 2024.
- Categories:
98 Views
To download this dataset without purchasing an IEEE Dataport subscription, please visit: https://zenodo.org/records/13896353
Please cite the following paper when using this dataset:
- Categories:
1054 Views
To download the dataset without purchasing an IEEE Dataport subscription, please visit: https://zenodo.org/records/13738598
Please cite the following paper when using this dataset:
- Categories:
1353 Views