Machine Learning

This dataset contains simulation data of the LightGBM controller for spacecraft attitude control. The data were generated using a closed-loop system of spacecraft attitude dynamics under an exact feedback linearization-based controller.
- Categories:
 116 Views
116 Views
The recording data include the following anthropometries: age (AG), weight (WE), height (HE), body mass index (BMI), waist circumference (WA), waist/height ratio (WHT), arm circumference (AR), hip circumference (HP), systolic blood pressure (BSY), diastolic blood pressure (DSY), heart rate (HR); the health indicator: glucose (DX); and the following functional fitness parameters: muscle (MM), visceral fat (VF), body fat (BF), and body age (BA). Ageing (AGG) is the ratio AG/BA.
- Categories:
18 Views
CucumberFlower
- Categories:
207 Views

Slow-rate DDoS attacks are recent threats targeting next-generation networks such as IoT, 5G, etc. Unlike conventional high-rate DDoS, slow-rate DDoS have not been deeply studied, mainly due to the limited number of existing datasets with real traces.
- Categories:
2731 Views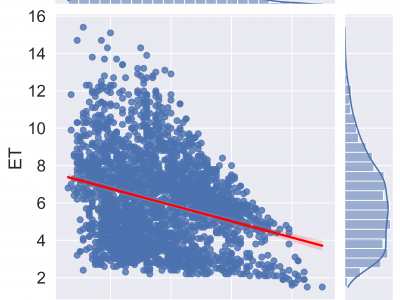
Reference Evapotranspiration (ETo) is the basic element of smart irrigation water management for sustainable developments in agriculture. Penman-Monteith (FAO-56 PM) is the standard method of ETo. The FAO-56 PM is complex in nature due to the requirements of many climatic conditions. Many existing machine learning-based solutions for simplification of ETo are limited to a specific area and not in accordance with the standard method FAO-56 PM.
- Categories:
194 Views
The dataset used in this study was derived from data collected from two courses offered on the University of Jordan's E-learning Portal during the second semester of 2020, namely "Computer Skills for Humanities Students" (CSHS) and "Computer Skills for Medical Students" (CSMS). Over the sixteen-week duration of each course, students participated in various activities such as reading materials, video lectures, assignments, and quizzes. To preserve student privacy, the log activity of each student was anonymized.
- Categories:
2609 ViewsBIMCV-COVID19+ dataset is a large dataset with chest X-ray images CXR (CR, DX) and computed tomography (CT) imaging of COVID-19 patients along with their radiographic findings, pathologies, polymerase chain reaction (PCR), immunoglobulin G (IgG) and immunoglobulin M (IgM) diagnostic antibody tests and radiographic reports from Medical Imaging Databank in Valencian Region Medical Image Bank (BIMCV).
- Categories:
453 Views
<p>Anonymized data used in the study of "<span style="font-family: Calibri, sans-serif; font-size: 11pt;">Administrative data processing, Clustering, classification, and association rules, Human factors and ergonomics, Machine learning"</span></p>
- Categories:
275 Views
Data preprocessing is a fundamental stage in deep learning modeling and serves as the cornerstone of reliable data analytics. These deep learning models require significant amounts of training data to be effective, with small datasets often resulting in overfitting and poor performance on large datasets. One solution to this problem is parallelization in data modeling, which allows the model to fit the training data more effectively, leading to higher accuracy on large data sets and higher performance overall.
- Categories:
105 Views