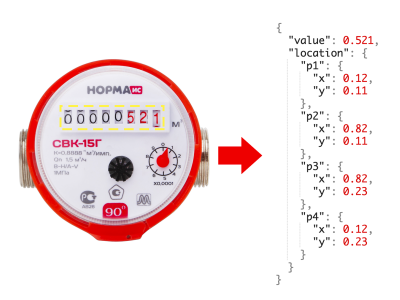
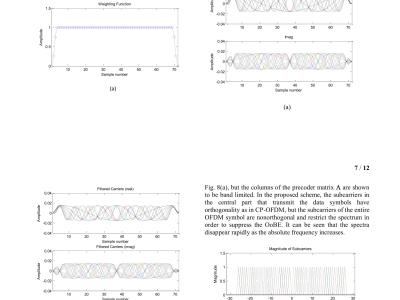
Following the successful completion of two collaboration projects on AI, IERE has proposed a third initiative. We are now extending this invitation for the "Artificial Intelligence (AI) Collaboration Project" to all IERE members, inviting your participation in this exciting opportunity.
Please kindly confirm your participation by sending the attached Answer Sheet to IERE Central Office by March 10, 2025.
We look forward to your positive response and active participation in this project.
- Categories: