
This dataset contains job and their skills extracted from the job adverisments.
- Categories:
This dataset contains job and their skills extracted from the job adverisments.

Experiments about satisfaction from ridesharing, from mturk
The first two experiemtns asked which explanations are likely to increase user satisfaction
The third experiment ask for satisfaction (1-7) given a scenario and some explanations. It's divided to three:
- pbe: explanations are all known info
- random: explanatiitons are random subset of knwon info
- axis: smart choosing of subset of the known info

The Baseline set described in the IEEE article (https://ieeexplore.ieee.org/document/10077565) as Baseline_set contains 1442450 rows, where the number of rows varied between 15395 and 197542 for the 16 subjects; the average per subject being 69095 rows. The data set is filtered and standardized as described in III.C in the submission . The other data sets used in the article are derived from Baseline set.
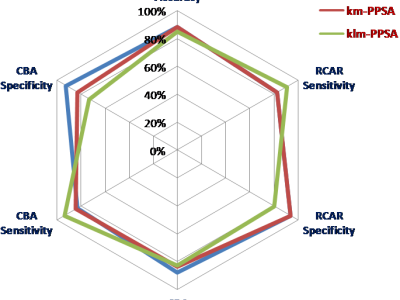
This dataset is used to illustrate an application of the "klm-based profiling and preventing security attack (klm-PPSA)" system. The klm-PPSA system is developed to profile, detect, and then prevent known and/or unknown security attacks before a user access a cloud. This dataset was created based on “a.patrik” user logical attempts scenarios when accessing his cloud resources and/or services. You will find attached the CSV file associated with the resulted dataset. The dataset contains 460 records of 13 attributes (independent and dependent variables).

Deployment of serverless functions depends on various factors. This dataset presents deployment time of a Python serverless function with various deployment package size, deployed on 6 regions of AWS and 6 regions of IBM. Deployment scripts are executed from Innsbruck, Austria.
Effects of the "spawn start" of the Monte Carlo serverless function that simulates Pi.
The functions are orchestrated as a workflow and executed with the xAFCL enactment engine (https://doi.org/10.1109/TSC.2021.3128137) on three regions (US, EU, Asia) of three cloud providers AWS Lambda, Google Cloud Functions, and IBM Cloud Functions.
100 instances of the Monte Carlo function are executed with "concurrency=30", which means that the first 30 functions are executed in parallel, while the rest 70 are invoked one after the other after some active function finishes.

This is a dataset that contains 50,000 transactions and 13 features/columns, the data set is used to perform market basket analysis in association rule mining.
A random function was used during the generation and the function generates random numbers of 0's and 1's for all 13 features of each transaction.
The probability of generating a 1 is twice as high as 0, this way there will be a strong or almost-strong association between the features.
1 means an item was purchased by the user and 0 means the item was not purchased.

This dataset contains 220,085 tweets containing the word vaccine between December 9th and December 18th 2021 at different times during each day, extracted using the Twitter API v2. Each tweet was extracted at least 3 days after its initial posting time in order to register 3 days of engagements, and it doesn't include retweets.
Includes:
Raspberry Pi benchmarking dataset monitoring CPU, GPU, memory and storage of the devices. Dataset associated with "LwHBench: A low-level hardware component benchmark and dataset for Single Board Computers" paper

Test of a robotic arm with a revolute joint in a MoCap system