*.csv

The dataset is generated using VISSIM, a microscopic traffic simulation software. The simulated environment accurately reproduces mixed traffic conditions involving both autonomous and conventional vehicles in the autonomous driving demonstration zone of Pangyo, South Korea. In setting up the simulation, various real-world factors are carefully incorporated, including the number and width of lanes, roadway gradients, and the configuration of traffic signal phase systems.
- Categories:
 377 Views
377 Views
This dataset is collected at KAIST, Daejeon, and KAIST by ISILAB to research seamless indoor-outdoor detection. The collecting device is a Raspberry Pi 4B+ with touchscreen UI connected with a Pmod Nav module and a PmodGPS. This collection has a rough three-month time span, which mitigates the specific time-specific bias. Further, in the collection, we also swap the wiring to simulate the device bias. The dynamic calibration is not applied to the dataset; searchers may choose to apply the dataset or not.
- Categories:
24 Views
Training and testing the accuracy of machine learning or deep learning based on cybersecurity applications requires gathering and analyzing various sources of data including the Internet of Things (IoT), especially Industrial IoT (IIoT). Minimizing high-dimensional spaces and choosing significant features and assessments from various data sources remain significant challenges in the investigation of those data sources. The research study introduces an innovative IIoT system dataset called UKMNCT_IIoT_FDIA, that gathered network, operating system, and telemetry data.
- Categories:
690 Views
The dataset are served for community-imbalanced graph sampling algorithm performance experiments. In the algorithm performance experiment, we selected 30 graph datasets, 15 of which were derived from real-world graph datasets (https://snap.stanford.edu/data/), and 15 were adapted from real-world datasets or simulated datasets.
- Categories:
33 Views
This is a dataset that contains the testing results presented in the manuscript "Exploring the Potential of Offline LLMs in Data Science: A Study on Code Generation for Data Analysis", and it aims to assess offline LLMs' capabilities in code generation for data analytics tasks. Best utilization of the dataset would occur after thorough understanding of the manuscript. A total of 250 testing results were generated for each of the two LLMs evaluated. They were merged, leading to the creation of this current dataset.
- Categories:
45 Views
The PermGuard dataset is a carefully crafted Android Malware dataset that maps Android permissions to exploitation techniques, providing valuable insights into how malware can exploit these permissions. It consists of 55,911 benign and 55,911 malware apps, creating a balanced dataset for analysis. APK files were sourced from AndroZoo, including applications scanned between January 1, 2019, and July 1, 2024. A novel construction method extracts Android permissions and links them to exploitation techniques, enabling a deeper understanding of permission misuse.
- Categories:
635 Views
This dataset was generated using high-fidelity air combat simulations to develop and evaluate Weapon Engagement Zone (WEZ) prediction models. It contains data for various Beyond Visual Range (BVR) air combat scenarios, capturing diverse conditions and configurations between a shooter aircraft and a target.
The dataset is split into factorial and random design datasets, with outputs representing critical WEZ parameters, including the maximum range (Rmax) and the no-escape zone (Rnez).
- Categories:
64 Views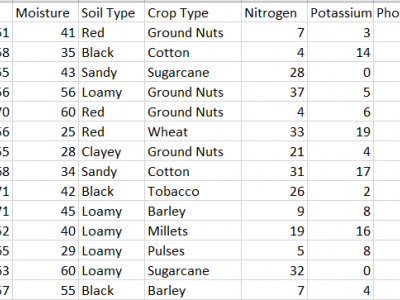
This dataset provides comprehensive data for predicting the most suitable fertilizer for various crops based on environmental and soil conditions. It includes environmental factors like temperature, humidity, and moisture, along with soil and crop types, and nutrient composition (Nitrogen, Potassium, and Phosphorous). The target variable is the recommended fertilizer name.
The data is already pre-processed without anu Null values.
- Categories:
1799 Views
This dataset contains survey responses collected from Agile practitioners across various roles, including Scrum Masters, Developers, Product Owners, and Agile Coaches, from organizations with diverse Agile practices. The survey aimed to identify the common challenges in backlog refinement, such as time constraints, prioritization issues, and ambiguous user stories. It also explored perceptions of Generative AI's role in streamlining Agile workflows, enhancing productivity, and reducing cognitive load.
- Categories:
84 Views
Please cite the following paper when using this dataset:
Vanessa Su and Nirmalya Thakur, “COVID-19 on YouTube: A Data-Driven Analysis of Sentiment, Toxicity, and Content Recommendations”, Proceedings of the IEEE 15th Annual Computing and Communication Workshop and Conference 2025, Las Vegas, USA, Jan 06-08, 2025 (Paper accepted for publication, Preprint: https://arxiv.org/abs/2412.17180).
Abstract:
- Categories:
148 Views