*.csv

The dataset contains:
- performance for random parameter values for the Embree datastructure on different scenes
- specific experiment data regarding the stability of triangle splitting, characterize by the angle of specific geometry
- partial tuning experiments, where parameters would be optimized while others would stay set
- Categories:
 91 Views
91 Views
Data consists of an EMG registry obtained with a hybrid electrostimulation and electromyography device. Electrodes were placed to record activity from the extensor muscle of the fingers while the subject was squeezing a hand gripper for 10 seconds and resting for another 10.
- Categories:
3017 Views
This dataset contains the output from 3D gait analysis. Over a period of 3 months, between January 1st and March 31st in 2019, 5 children were familiarized with the Hibbot by using the walking aid for 30 minutes, twice a week, under the supervision of a physiotherapist.
- Categories:
221 Views
EmoSurv is a dataset containing keystroke data along with emotion labels. Timing and frequency data is recorded while participants are typing free and fixed texts before and after being induced specific emotions. These emotions are: Anger, Happiness, Calmness, Sadness, and Neutral state.
First, data is collected while the participant is in a neutral state. Then, the participant watches an eliciting video. Once the emotion is induced in the participant, he types another fixed and free text.
- Categories:
3648 Views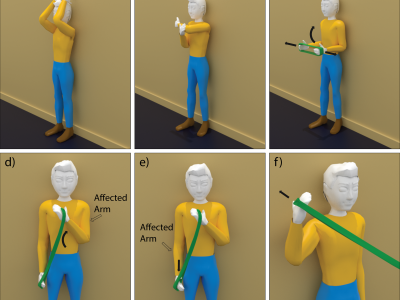
Shoulder Physiotherapy Activity Recognition 9-Axis Dataset (SPARS9x)
Suggested uses of this dataset include performing supervised classification analysis of physiotherapy exercises, or to perform out-of-distribution detection analysis with unlabeled activities of daily living data.
Description:
- Categories:
1795 Views
The dataset provides Abilify Oral user reviews and ratings for drug’s satisfaction, effectiveness, and ease of use on different age groups.
- Categories:
295 Views
A dataset of the senior high students.
The dataset contains :
1_teacher.csv contains the corresponding information of the teachers;
2_student.csv contains the corresponding information of the students;
3_kaoqin.csv contains the attendance information of the students;
4_kaoqintype.csv contains the type of attendance.
5_chengji.csv contains the grades of the students.
6_exam_type.csv contains the type of examinations.
- Categories:
747 Views
The dataset is composed of digital signals obtained from a capacitive sensor electrodes that are immersed in water or in oil. Each signal, stored in one row, is composed of 10 consecutive intensity values and a label in the last column. The label is +1 for a water-immersed sensor electrode and -1 for an oil-immersed sensor electrode. This dataset should be used to train a classifier to infer the type of material in which an electrode is immersed in (water or oil), given a sample signal composed of 10 consecutive values.
- Categories:
2353 Views
This dataset contains the experimental materials for "Use and Perceptions of Multi-Monitor Workstations".
There are two files:
- survey.txt: the survey questions
- survey-results.csv: the answers obtained from the 101 respondents tot he survey
- Categories:
127 Views
Most text-simplification systems require an indicator of the complexity of the words. The prevalent approaches to word difficulty prediction are based on manual feature engineering. Using deep learning based models are largely left unexplored due to their comparatively poor performance. We have explored the use of one of such in predicting the difficulty of words. We have treated the problem as a binary classification problem. We have trained traditional machine learning models and evaluated their performance on the task.
- Categories:
2741 Views