*.avi; *.csv; *.txt; *.zip

This study presents a comprehensive dataset to analyze risk factors associated with cardiovascular disease. The dataset comprises various patient attributes, including gender, age, total cholesterol, HDL (high-density lipoprotein), triglycerides, non-HDL (non-high-density lipoprotein), NIH-Equ-2, and direct LDL (low-density lipoprotein). These attributes comprise 25,991 patient data, robustly representing a large population sample.
- Categories:
 593 Views
593 Views
In this letter, a novel shrinking long period fiber grating(S-LPFG) is designed. This strain sensor is fabricated through mechanical polishing and arc-discharging, allowing for certain control over its sensitivity to strain. The single-mode fiber(SMF) is first preprocessed into a D-shaped fiber(DSF) through polishing. Then, a periodic melting-induced shrinking is applied to the fiber through arc-discharging modulation. The polishing and shrinking enhance the asymmetry of the single-mode fiber.
- Categories:
11 Views
This data repository contains test data and corresponding test code for evaluating the performance of a machine learning model. The dataset includes 950 labeled samples across 7 different classes. The test code provides implementations of several common evaluation metrics, including accuracy, precision, recall, and F1-score. This resource is intended to facilitate the benchmarking and comparison of different machine learning algorithms on a standardized task.
- Categories:
36 Views
Description: This supplementary materials file contains:
-All raw data generated in the experiments.
-All MATLAB files required to update the ForceSight application with new data.
-A video of the test procedure for a contraction force measurement of an example actuator.
-License files for BioRender.com
Size: Less than 250 MB
Platform: MATLAB
Environment: Microsoft, Linux, MacOS
Major component description:
- Categories:
54 Views
The python code of Graph Neural Network (GRN). Recent studies have shown that the predictive performance of graph neural networks (GNNs) is inconsistent and varies across different experimental runs, even with identical parameters. The prediction variability limits GNNs' applicability, and the underlying reasons remain unclear. We have identified a key factor contributing to this issue: the oscillation of some nodes' predicted classes during GNN training.
- Categories:
10 Views
This is the PSCAD simulation for the article "Grid Impedance Adaptive VSG Control Based on Accurate Small-Signal Modelling".
- Categories:
530 Views
This dataset is designed for the purpose of curve fitting, a key process in the reconstruction of implicit curves. It encompasses a collection of point cloud data that has been sampled directly from curves, as well as the code necessary to generate point cloud data from these curves.
- Categories:
151 Views
The goal of the Smart* project is to optimize home energy consumption. Available here is a wide variety of data collected from three real homes, including electrical (usage and generation), environmental (e.g., temperature and humidity), and operational (e.g., wall switch events). Also available is minute-level electricity usage data from 400+ anonymous homes.
- Categories:
1056 Views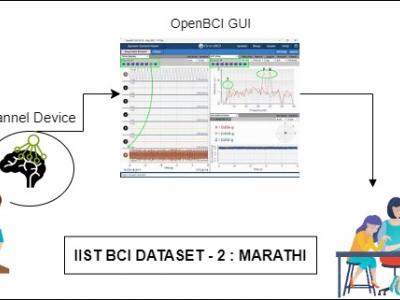
Problems of neurodegenerative disorder patients can be solved by developing Brain-Computer Interface (BCI) based solutions. This requires datasets relevant to the languages spoken by patients. For example, Marathi, a prominent language spoken by over 83 million people in India, lacks BCI datasets based on the language for research purposes. To tackle this gap, we have created a dataset comprising Electroencephalograph (EEG) signal samples of selected common Marathi words.
- Categories:
527 Views
These datasets are gathered from an array of four gas sensors to be used for the odor detection and recognition system. The smell inspector Kit IX-16 used to create the dataset. each of 4 sensor has 16 channels of readings. Odors of different 12 samples are taken from these six sensors
1- Natural Air
2- Fresh Onion
3- Fresh Garlic
4- Black Lemon
5- Tomato
6- Petrol
7- Gasoline
8- Coffee
9- Orange
10- Colonia Perfume
- Categories:
471 Views